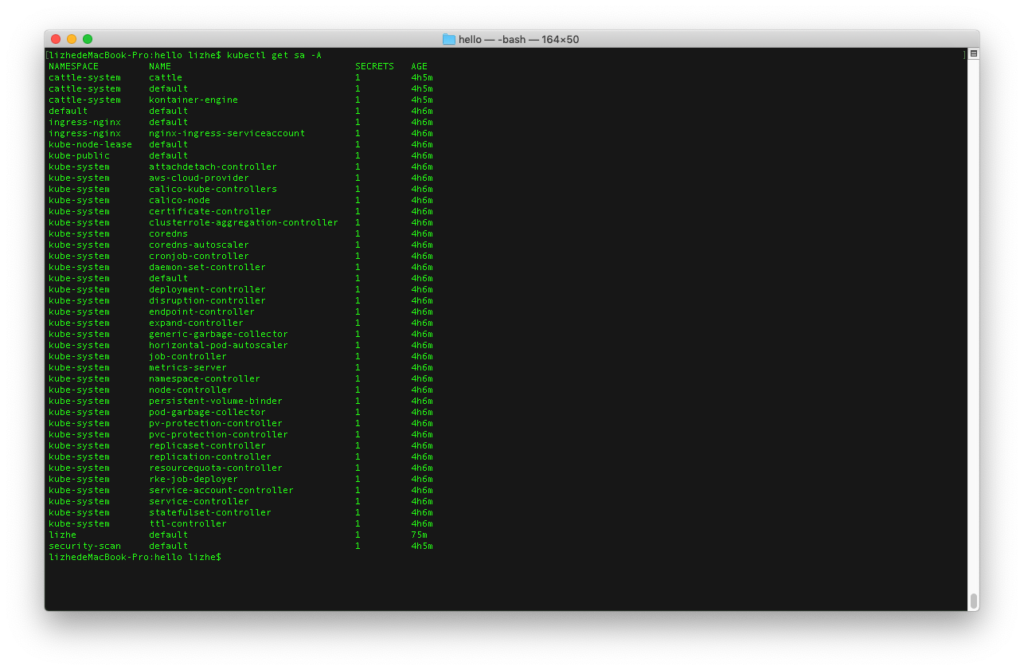
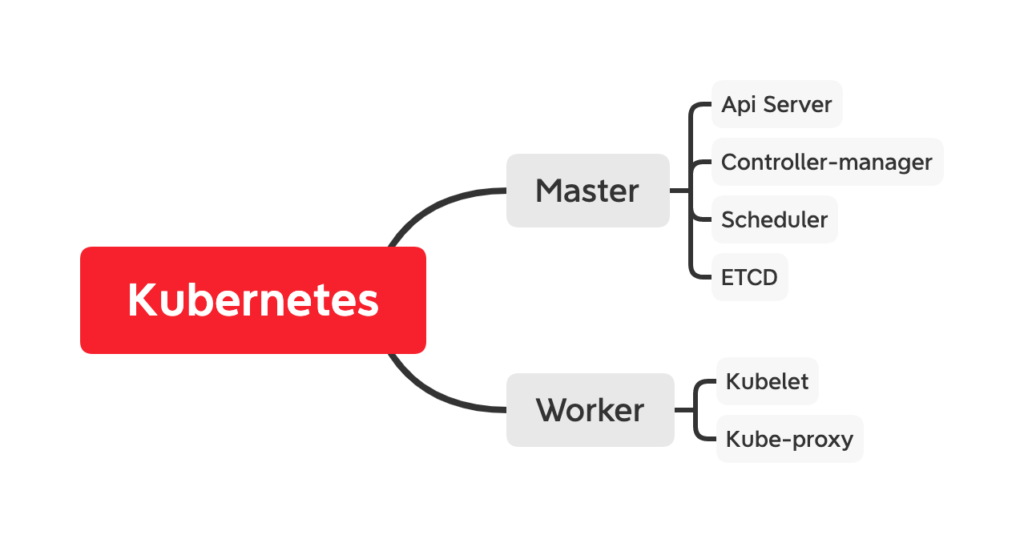
Kubernetes scheduling process
The core of kubernetes scheduler is two independent control loops
- Informer Path
- Scheduling Path
Informer is responsible for monitoring the changes of API objects related to scheduling such as pod, node and service in etcd.
Scheduling is the main cycle responsible for scheduling. Its main function is to continuously extract pod from the scheduling queue, and then score the node 0-10 according to the node information obtained from the scheduler cache. The node with the highest score is the result of this scheduling
After the scheduling algorithm is completed, the scheduler modifies the NodeName field value of the Pod object to the name of the above node, called bind.
Predictions before priorities
There are four default scheduling policies in kubernetes:
GeneralPredicates
The most basic scheduling strategy, such as calculating whether CPU and memory resources are enough
- Volume related filtering rules
Check whether PV conflicts, etc
- Host related rules
Check node stains, etc
- Pod related filtering rules
Check pod affinity, etc
The above four strategies are used as filters to determine whether a node can run the pod to be scheduled
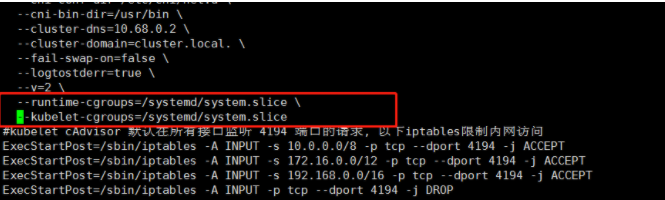
In order not to remotely access the API server in the critical scheduling path, kubernetes will only update the pod and node information in the scheduler cache in the bind phase of the default scheduler. This API object update method based on optimistic assumptions is called assume.
After Assume is completed, the scheduler will create a Goroutine to initiate an update Pod request to API Server asynchronously to complete the Bind operation. If the asynchronous request fails, everything will return to normal after the scheduler cache is synchronized.
After the end of the asynchronous bind and before the new pod is actually scheduled, kubelet Haihui on the node verifies again whether the pod can run on the node through an operation called admit, that is, execute the basic scheduling algorithm of general predictions (whether the resources are available and whether the end ports conflict) again as kubelet’s secondary confirmation.
The job of the optimization strategy is to score these nodes
The most commonly used scoring rule for preference strategy is leadrequestedpriorityThe longest used scoring rule for the preference strategy is LeastRequestedPriority
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacityWorking with LeastRequestedPriority is also the BalancedResourceAllocation
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10The definition of the fraction of each resource is the resource requested by the pod / the available resources on the node. The function of the variance algorithm is to calculate the “distance” between each two resource fractions, and finally select the node with the smallest resource fraction gap.
BalancedResourceAllocation selects the node with the most balanced resource allocation among all nodes, so as to avoid the situation that a large amount of CPU is allocated and a large amount of memory is left on a node
In addition, there are three preferred strategies: nodeaffinitypriority, tainttolerationpriority and interpodaffinitypriority. As a preferred strategy, the more fields a node satisfies the above rules, the higher its score will be
In the default preference policy, there is also a policy called imagelocalpriority. It’s in kubernetes v1 The scheduling rule provided in 12, that is, if the pod to be scheduled needs to use a large image and already exists on some nodes, the scores of these nodes will be relatively high
Of course, in order to avoid scheduling stack, the scheduler will optimize the score according to the distribution of images, that is, if the number of nodes distributed in large images is small, the weight of these nodes will be reduced, so as to hedge the risk of scheduling stack.