kube-scheduler
Scheduler operates in a way that multiple people are responsible for the same work and then activate a main work node based on voting.
The leader election mechanism can ensure high availability, but there is only one scheduler node working normally, and other nodes are blocked as candidate nodes.
After the leader node quits for some reason, other candidate nodes run for election through the election mechanism. The node that becomes the new leader will take over the work of the original node.
The election mechanism is implemented through distributed locks,
- The distributed lock depends on a key on etcd. The operations of the key are atomic operations. Taking the key as a distributed lock, it has two states – existence and nonexistence.
- When the key (distributed lock) does not exist: a node in multiple nodes successfully creates the key (obtains the lock) and writes the information of its own node. The node that obtains the lock is called the leader node. The leader node will regularly update (renew) the information of the key.
- When a key (distributed lock) exists: other nodes are blocked and acquire locks regularly. These nodes are called candidate nodes. The process of the candidate node obtaining the lock regularly is as follows: obtain the data of the key regularly and verify whether the leader lease in the data expires. If it does not expire, it cannot be preempted. If it has expired, update the key and write the information of its own node. If the update is successful, it will become the leader node.
As we all know, the main function of the scheduler is to find the most suitable node node in the cluster for the newly created pod (in fact, if the pod needs to be migrated), and schedule the pod to this node.
- Select available nodes first
- Reselect the optimal node
- If pod is used Spec.nodename enforces the constraint to schedule the pod to the specified node. Bypassing the scheduler will not check the human resources
The scheduling core consists of two independent control loops
One is the list watch mechanism and cache mechanism on the informer path loop
One is the pre selection mechanism and binding callback mechanism on the scheduler path loop
First control loop informer path
The main purpose is to start a series of informers to monitor the changes of pod, node, Sservice and other API objects related to scheduling in etcd.
Example: when a pod to be scheduled (nodeName field is empty) is created, the scheduler will add the pod to be scheduled to the scheduling queue through the handler of pod informer.
By default, the kubernetes scheduling queue is a priority queue, and when some cluster information changes, the scheduler will perform special operations on the contents of the scheduling queue. It is mainly due to the consideration of scheduling priority and preemption.
Responsible for updating the scheduler cache. Kubernetes scheduling is the most fundamental principle for performance optimization. It caches the cluster information as much as possible to improve the execution efficiency of predict and priority scheduling algorithms.
In the second control loop,
the scheduler is responsible for the scheduling path of the main loop of pod scheduling
Main logic: constantly leave the pod from the scheduling queue and call the predictions algorithm for “filtering”. “Filter” to get a group of nodes, that is, a list of all hosts that can run this pod. The node information required by the predictions algorithm is directly obtained from the scheduler cache to ensure the execution efficiency of the algorithm.
The scheduler will call the priorities algorithm to score the nodes in the above list from 0 to 10. The node with the highest score is the result of scheduling.
After the execution of the scheduling algorithm, the scheduler needs to fill the value of the nodeName field of the Pod object into the Node name. = = = = > Bind phase.
The specific location is
/home/lizhe/k8s/kubernetes/pkg/scheduler/scheduler. go
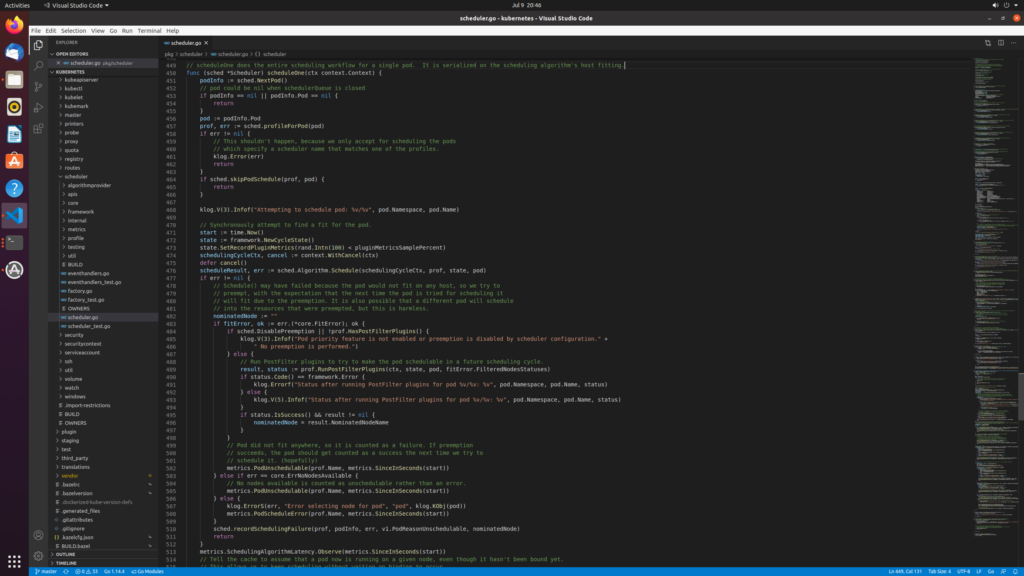
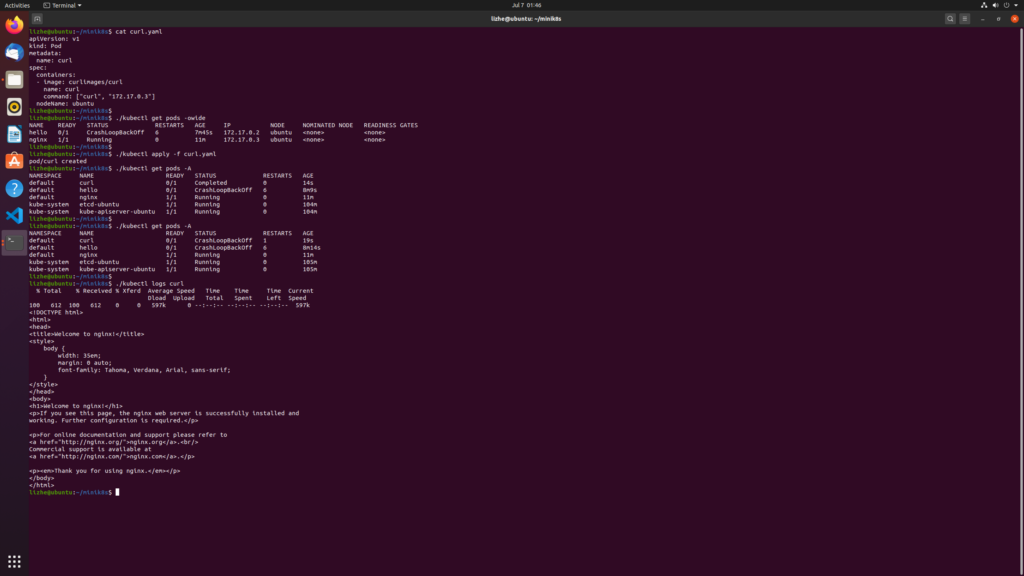
Here, I remove the nodeName in the previous example and apply nginx again
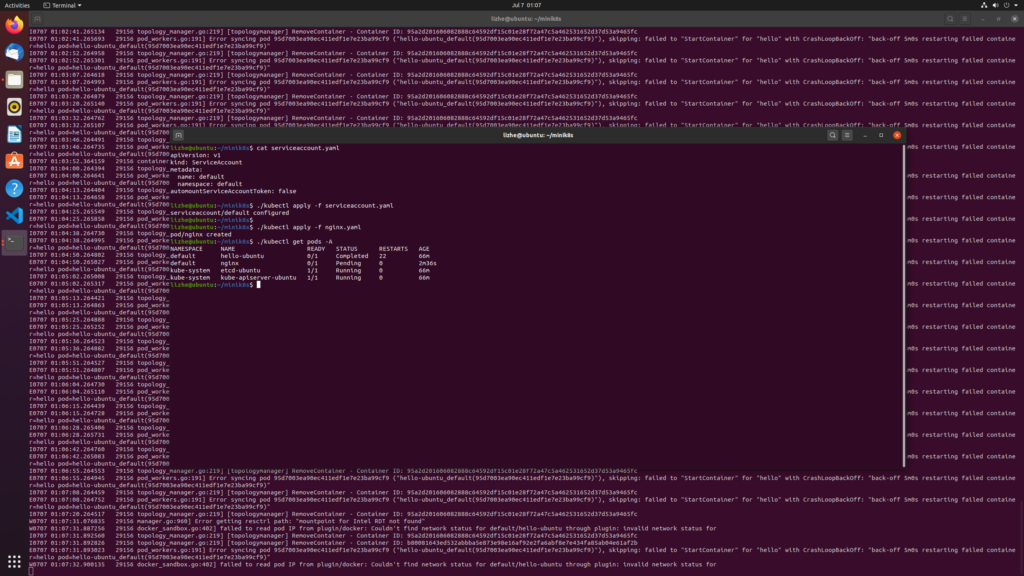
It can be seen that without starting Kube scheduler, pod cannot be correctly assigned to node and will always be in pending state
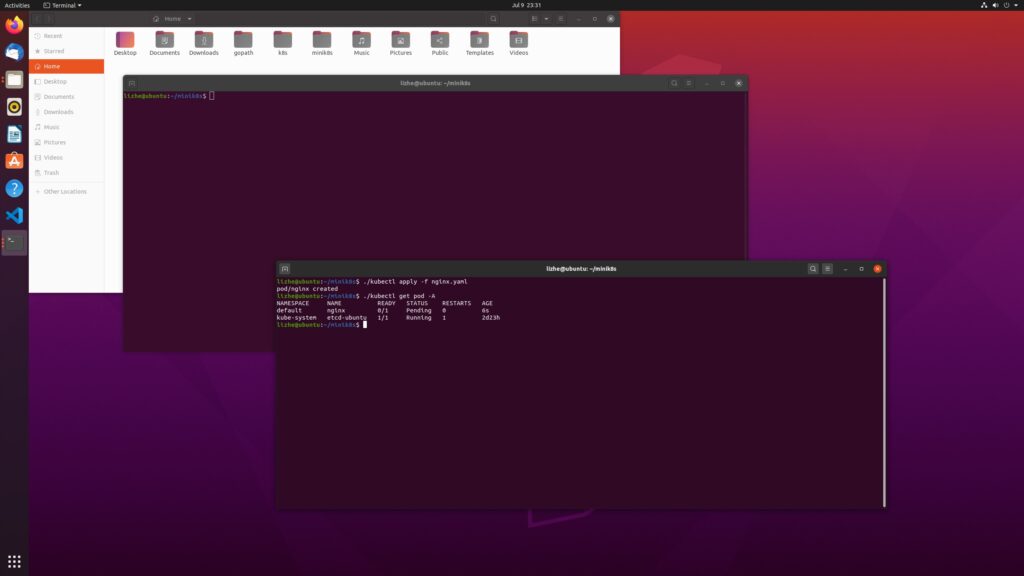
start kube-scheduler
./kube-scheduler --kubeconfig=kubeconfig.yamlRe create nginx pod and you will find that it is still pending
By checking the pod information, it is found that the node holds the unallocated taint by default
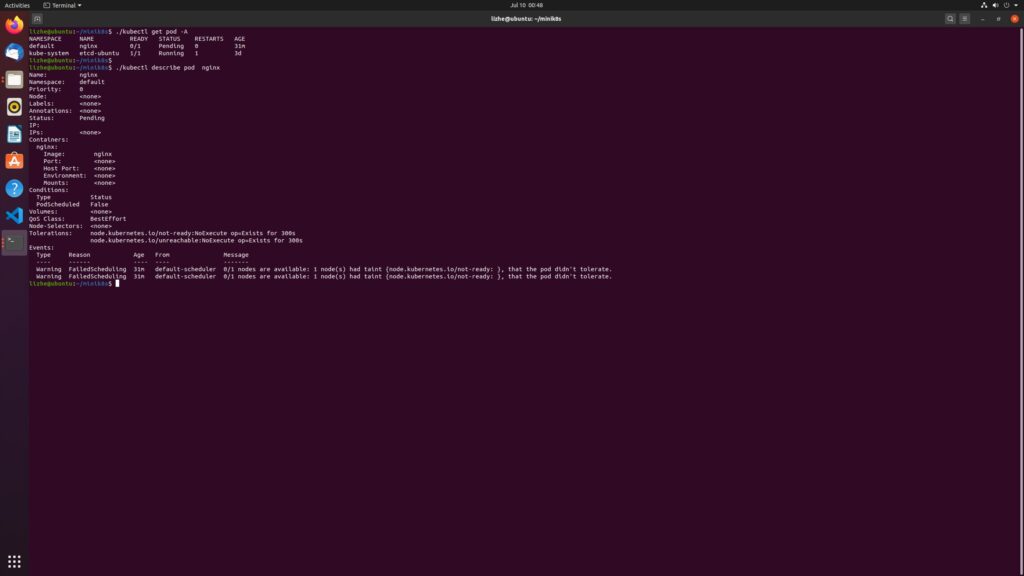
Next, I try to delete this taint
./kubectl taint nodes ubuntu node.kubernetes.io/not-ready:PreferNoSchedule-
./kubectl taint nodes ubuntu node.kubernetes.io/not-ready:NoSchedule-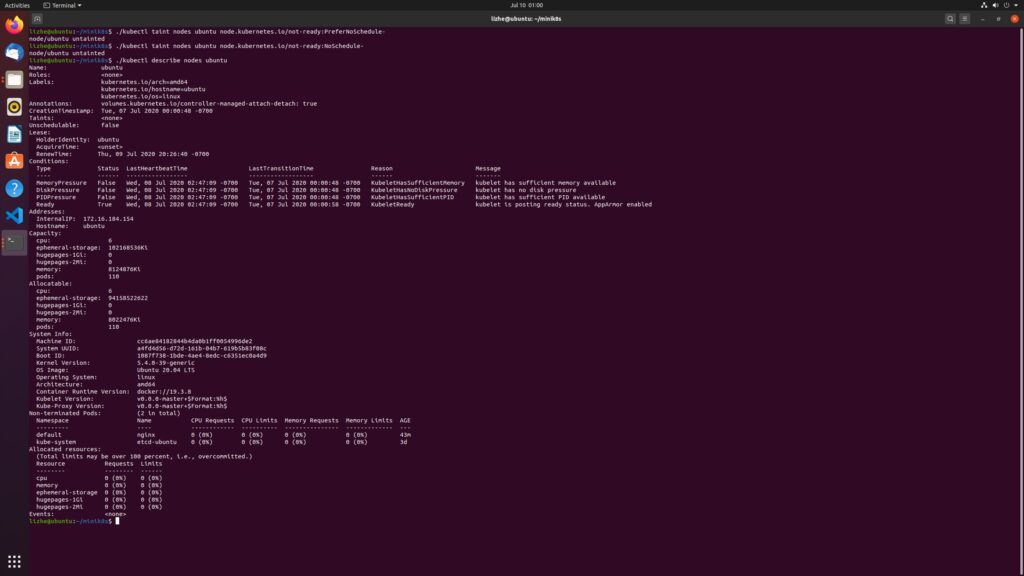
After deleting taint, you can see that the scheduler does allocate node to pod
However, the pod status is still pending
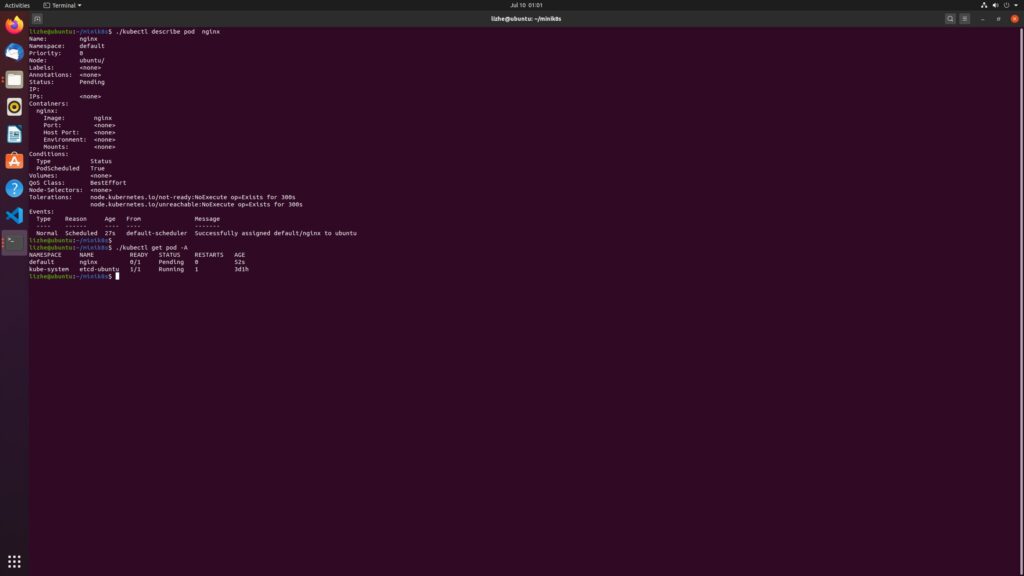
We have seen that the scheduler successfully allocated node
However, kubelet does not seem to create the instance of pod correctly, and the status of pod is still pending. Why?