Redis cluster 使用
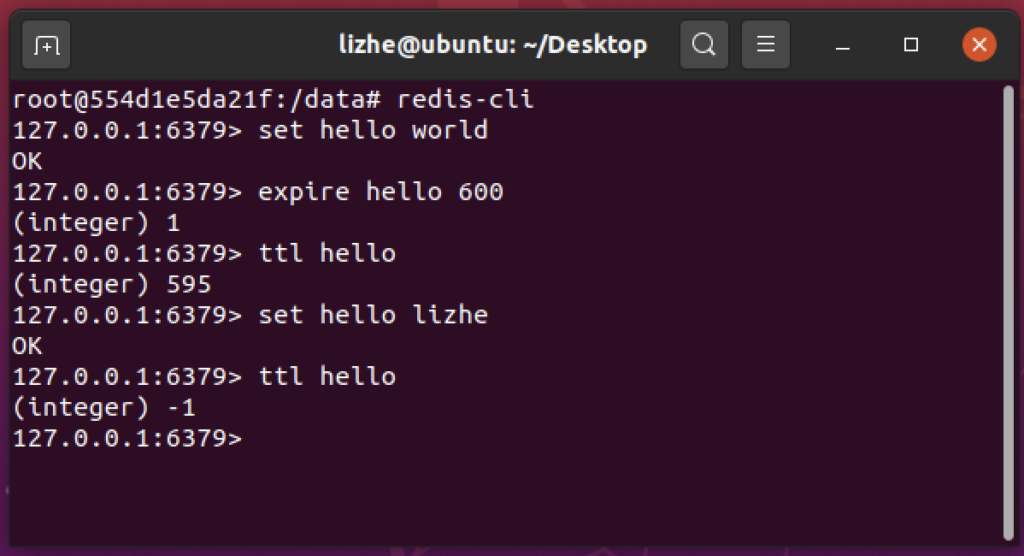
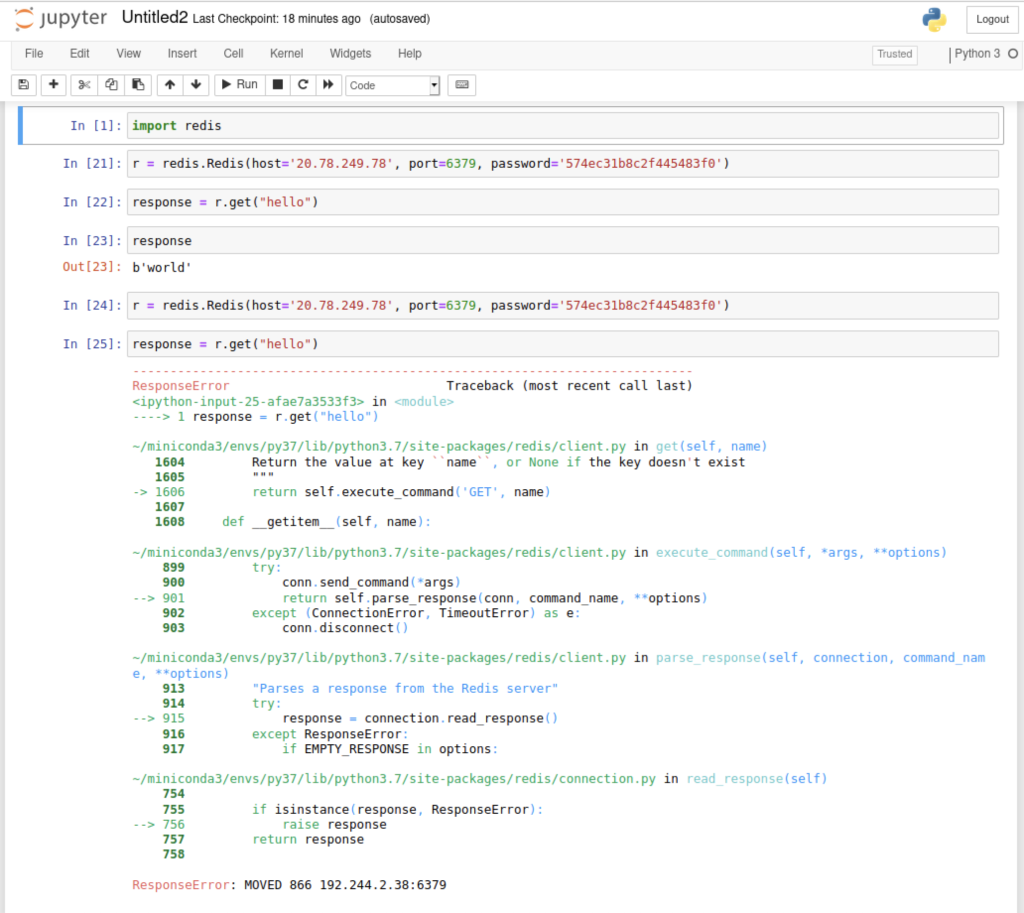
由于是通过不同的 hash slot 来分配存储的所以使用 keys * 可能并不能让你获得全部的key
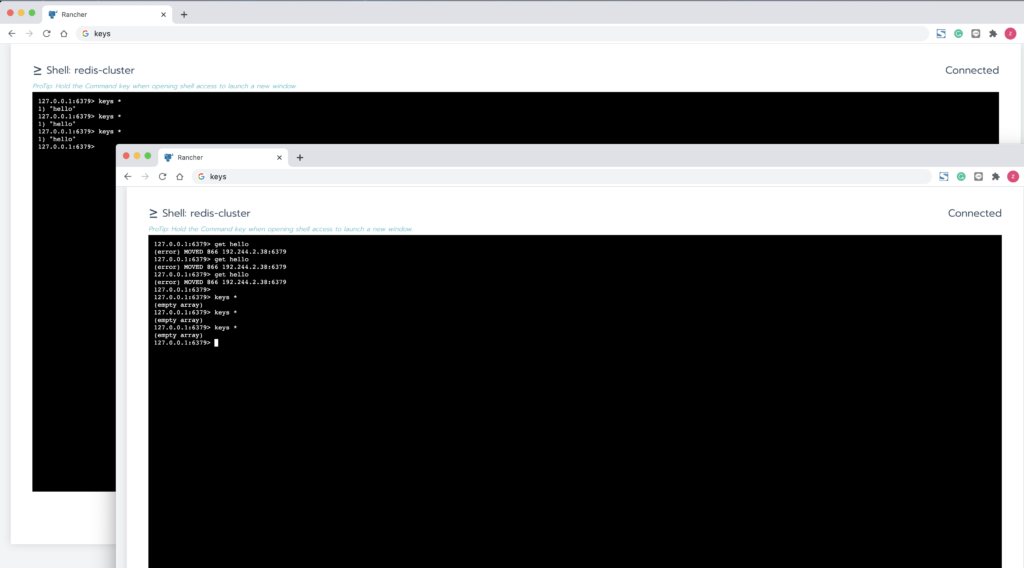
在slave节点上进行存储的时候,会跳转给对应的master
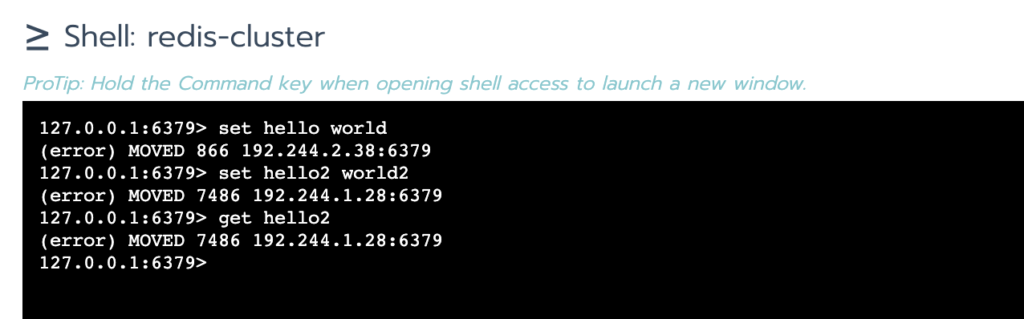
redis-cli 只是返回 error 并不会真的帮你 moved 到 28 然后进行 set
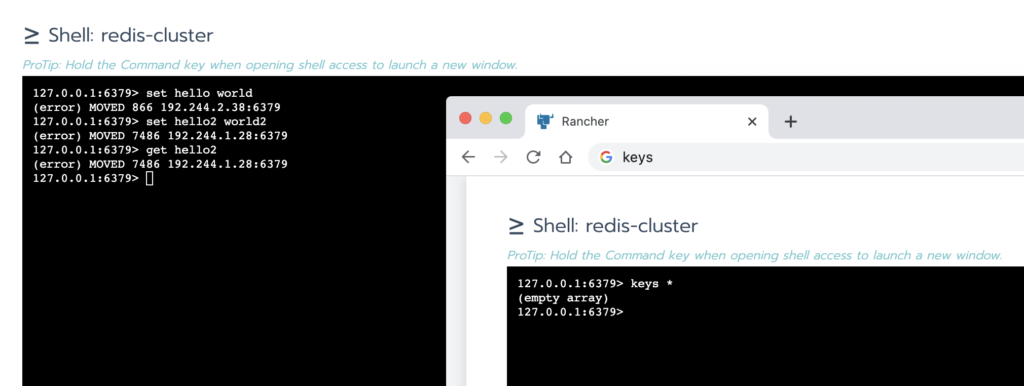
redis-cluster 的客户端可能需要自己处理 moved 动作,而不是简单的通过LB就可以使用
由于是通过不同的 hash slot 来分配存储的所以使用 keys * 可能并不能让你获得全部的key
在slave节点上进行存储的时候,会跳转给对应的master
redis-cli 只是返回 error 并不会真的帮你 moved 到 28 然后进行 set
redis-cluster 的客户端可能需要自己处理 moved 动作,而不是简单的通过LB就可以使用
本文将使用 redis cluster模式来构建一个redis集群
redis cluster 会按照hash槽来分布存储数据,主节点将会有3个,并且自带主从,所以3个主节点还会有3个从节点
redis.conf 配置文件参考,这里是 6.2 版本
https://raw.githubusercontent.com/antirez/redis/6.2/redis.conf
这里会在一台宿主机上使用6个docker容器来构建
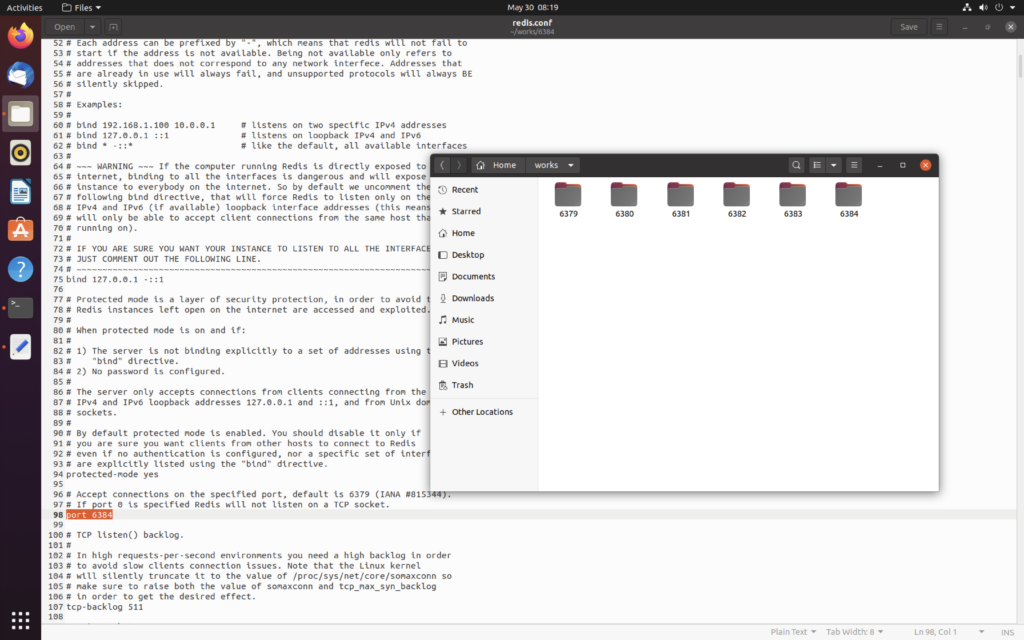
redis.conf 中需要修改以下几个内容
核心配置文件是
bind * -::*
port 6379
dir /data
cluster-enabled yes
cluster-config-file nodes-6379.conf
appendonly yes
appendfsync always
daemonize yes然后使用 docker-compose.yml 创建集群
version: "3.4"
x-image:
&default-image
redis:latest
x-restart:
&default-restart
always
x-command:
&default-command
redis-server /etc/redis/redis.conf
x-netmode:
&default-netmode
host
services:
redis1:
image: *default-image
restart: *default-restart
container_name: redis6-m1
command: *default-command
volumes:
- ./6379/data:/data
- ./6379/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode
redis2:
image: *default-image
restart: *default-restart
container_name: redis6-m2
command: *default-command
volumes:
- ./6380/data:/data
- ./6380/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode
redis3:
image: *default-image
restart: *default-restart
container_name: redis6-m3
command: *default-command
volumes:
- ./6381/data:/data
- ./6381/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode
redis4:
image: *default-image
restart: *default-restart
container_name: redis6-s1
command: *default-command
volumes:
- ./6382/data:/data
- ./6382/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode
redis5:
image: *default-image
restart: *default-restart
container_name: redis6-s2
command: *default-command
volumes:
- ./6383/data:/data
- ./6383/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode
redis6:
image: *default-image
restart: *default-restart
container_name: redis6-s3
command: *default-command
volumes:
- ./6384/data:/data
- ./6384/redis.conf:/etc/redis/redis.conf
network_mode: *default-netmode

创建并初始化集群
redis-cli --cluster-replicas 1 --cluster create 192.168.194.189:6379 192.168.194.189:6380 192.168.194.189:6381 192.168.194.189:6382 192.168.194.189:6383 192.168.194.189:6384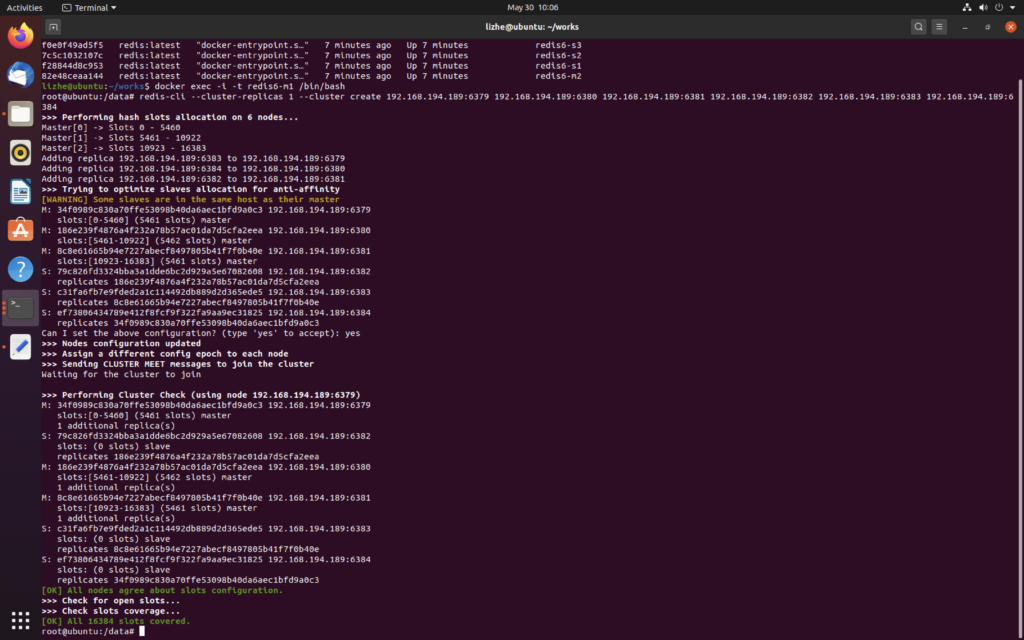

scan 比 keys 高级一些,2.8版本之后加入
scan的第一个参数是 游标值,第二个参数是 正则,第三个参数是 limit
scan 会返回一个数组,0 位置是 下一个游标值,1 位置是 结果集数组
下面这个例子中 一共有5个元素,scan返回0 时代表没有新游标了,scan 0 表示开启一个新会话
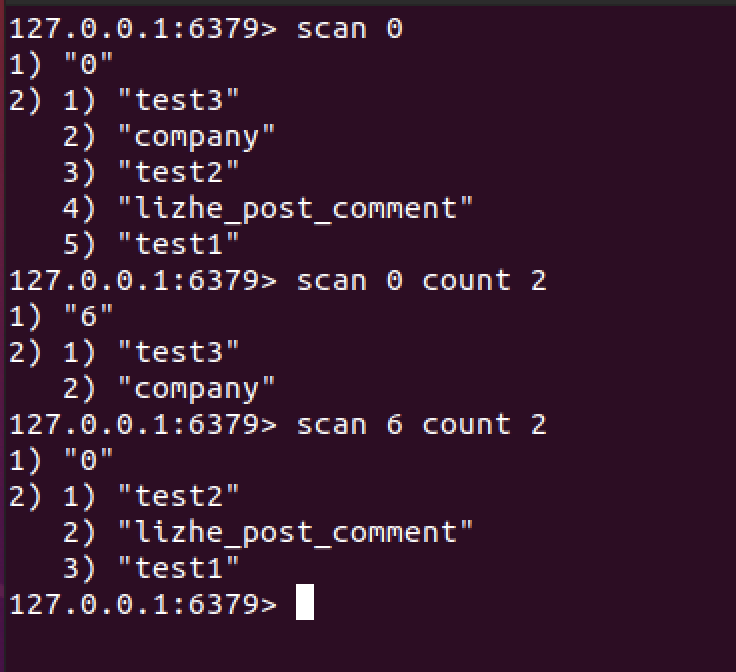
scan 0 count 2 只返回了2个元素,并且提示了下一个游标值是6
使用6再次scan,返回了后续的3个元素
为什么count 2 却返回了3个元素?数据量太小的情况下,count有可能会失效,这是一个scan的痛点

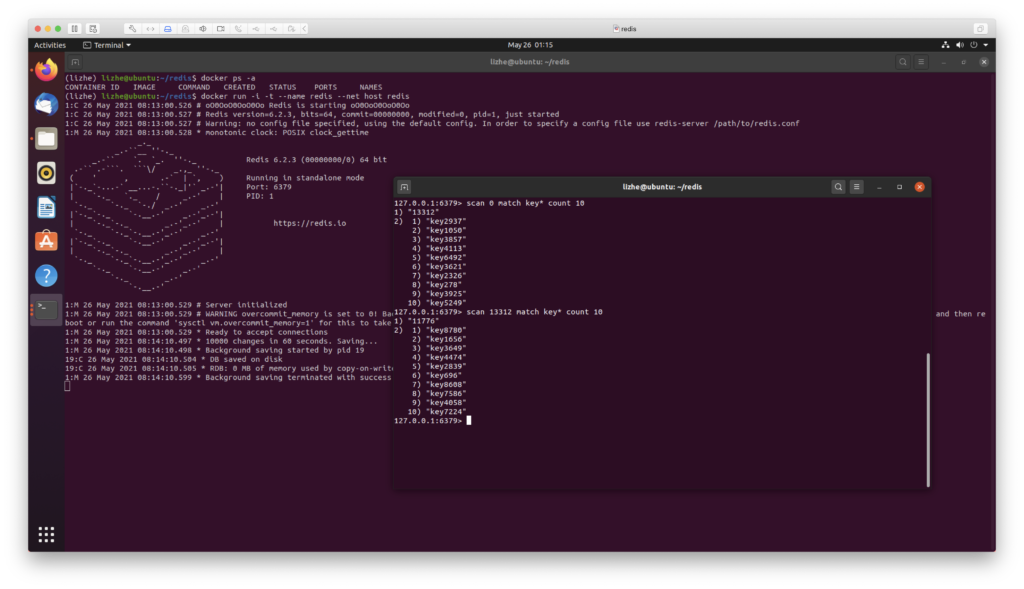
如果你尝试 从 10000条记录中,分两次各取5000,你会发现scan的 count 照样不靠谱
第一次 5002
第二次 4998
Redis 是一个单线程程序 ( nginx 也是一个单线程程序 )
Redis 所有的数据都在内存中,所有的运算都是内存级别的运算。
Redis 主要依赖 多路复用 和 异步IO 来维持性能
业界比较通用的地理位置距离排序算法是 GeoHash 算法, Redis 也使用 GeoHash 算法。GeoHash算法将 二维的经纬度数据映射到一维的整数,这样所有的元素都将挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间的距离也会很接近。
Redis提供了6个Geo指令
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2
127.0.0.1:6379> 
2. geodist
127.0.0.1:6379> geodist company jd xiaomi km
"33.0047"
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> 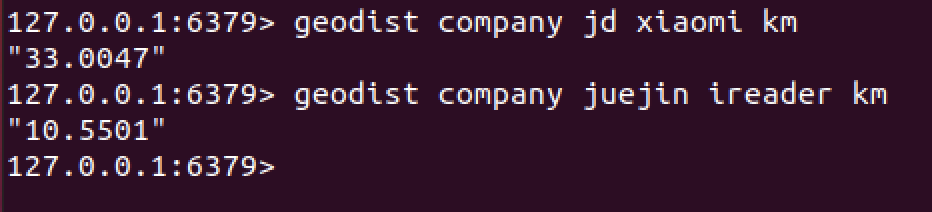
3. 获取元素的 hash 值
geohash company jd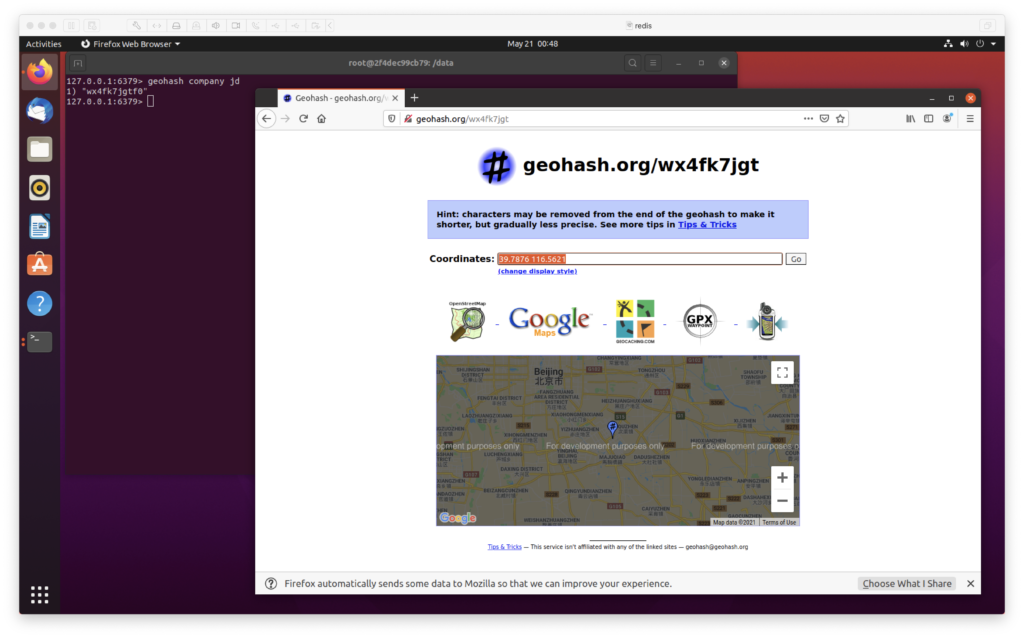
4. georadiusbymember
用来查询指定元素附近的其他元素
4.1 范围20公里以内最多 3个 元素 按距离 倒排,它不会排除自身
127.0.0.1:6379> georadiusbymember company jd 20 km
1) "jd"
2) "ireader"
127.0.0.1:6379> georadiusbymember company jd 20 km count 3
1) "jd"
2) "ireader"
127.0.0.1:6379> georadiusbymember company jd 20 km count 3 desc
1) "ireader"
2) "jd"
127.0.0.1:6379> 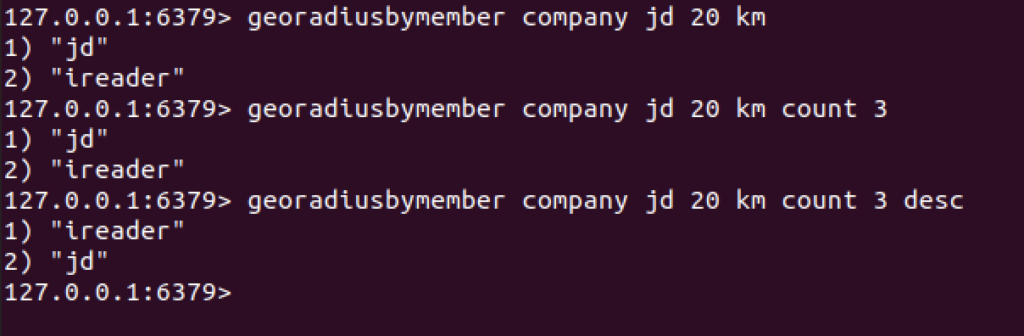
4.2 同时返回距离
georadiusbymember company jd 20 km count 3 desc withdist
5. 直接使用坐标
127.0.0.1:6379> georadius company 116.334255 40.027400 20 km count 3 desc withdist
1) 1) "juejin"
2) "12.9604"
2) 1) "xiaomi"
2) "0.0002"
127.0.0.1:6379>

6. 获取元素位置
geopos company jd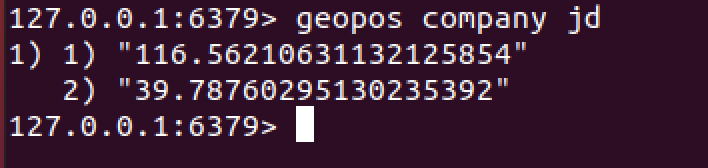
简单限流策略的意义在于,系统要限定用户的某个行为在指定的时间里只能发生 N 次。
这里使用的是一个 zset + 滑动窗口
核心思想是,zset包含一个 key、一个value、一个score
key = 用户名 + 动作
value = uuid 因为是不能重复的,也可以是时间戳
score = 时间戳
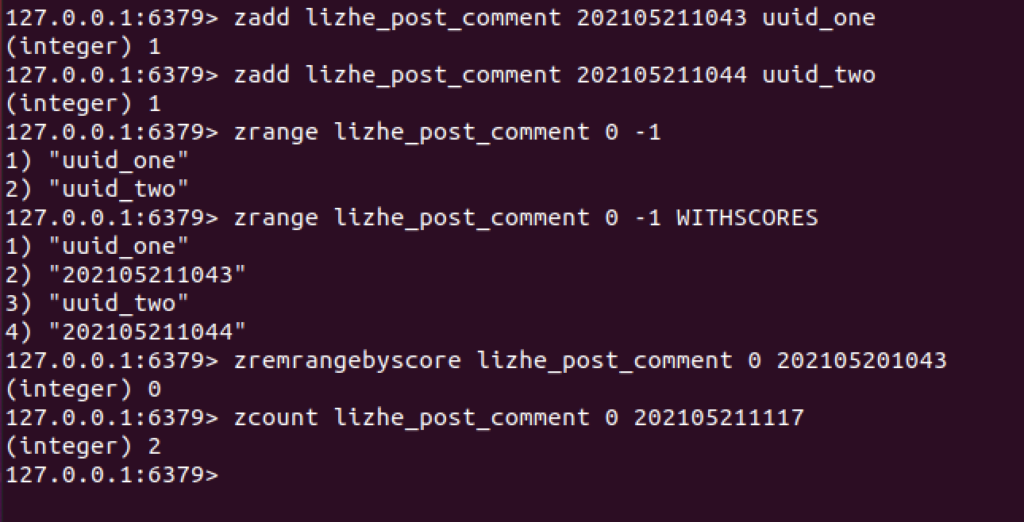
假设现在的需求是,一个用户,在一天之内,只能提交2次 评论,那么每次用户提交comment之后
用户提交2次评论,就会添加2条记录
127.0.0.1:6379> zadd lizhe_post_comment 202105211043 uuid_one
(integer) 1
127.0.0.1:6379> zadd lizhe_post_comment 202105211044 uuid_two
(integer) 1
127.0.0.1:6379>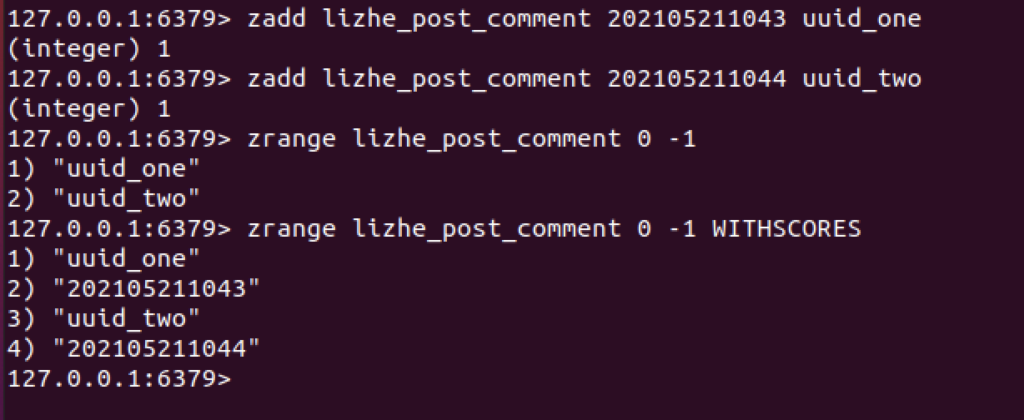
下面开始一个标准添加流程
每次添加记录时,要先进行 数据清洗 + 数据统计
数据清洗 需要 zremrangebyscore , 它会删除分数区间段内的元素,参数时 起始 score 和 终止 score
这里再每次存储之前,因为需求是 1天之内,那么应该删除24小时之前的数据
zremrangebyscore lizhe_post_comment 0 2021052010432. 第二步
然后进行统计
zcount lizhe_post_comment 0 202105211117 此时可以得到 没有过期的 操作记录数,这里是 2
然后判断是否符合 1天之内,提交2次的限制,决定是否继续
可以把 布隆过滤器 理解成一种特殊的,不太精确的set结构,当你使用它的 contains方法判断某个对象是否存在时,它可能会误判。
当 布隆过滤器 说某个值存在时,这个值可能不存在。
当 布隆过滤器 说某个值不存在时,这个值肯定不存在。
Bloom 过滤器是一种插件,也可以直接用安装好的镜像
docker run -i -t -d --name redisbloom -p 6379 redislabs/rebloom下面是一些操作例子
127.0.0.1:6379> bf.add students lizhe
(integer) 1
127.0.0.1:6379> bf.add students jon
(integer) 1
127.0.0.1:6379> bf.exists students lizhe
(integer) 1
127.0.0.1:6379> bf.mexists students lizhe jon tony
1) (integer) 1
2) (integer) 1
3) (integer) 0
127.0.0.1:6379> bf.madd students user1 user2 user3
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> del students user1
(integer) 1
127.0.0.1:6379> del students user2
(integer) 0
127.0.0.1:6379> del students user3
(integer) 0
127.0.0.1:6379>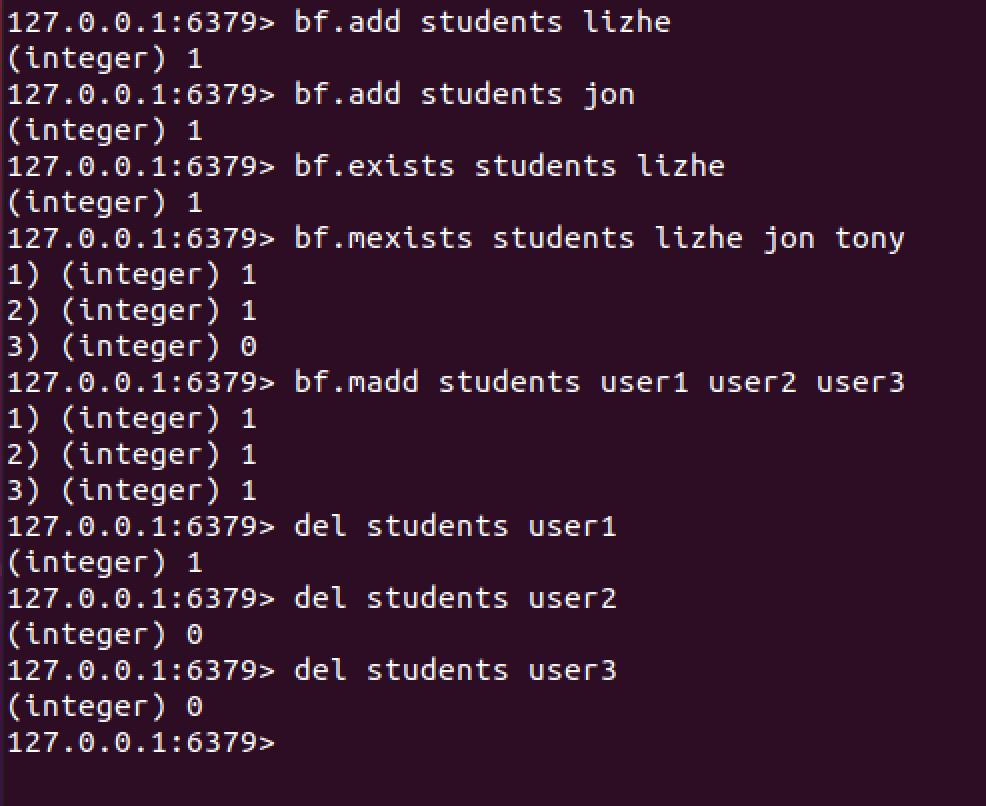
每个布隆过滤器对应的 redis 数据结构 是一个大型的 位数组 和几个不一样的 无偏 hash 函数
所谓无偏,就是能把元素的hash值算得比较均匀,让元素被hash映射到位数组中的位置比较随机。
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash,算得一个整数索引值,然后对位数组长度进行取模算得一个位置,每个hash函数都会算得一个不同的位置,再把这些位置都设置为 1 , 就完成了 add 动作。
询问元素是否存在时,也会把hash再算一遍,确定出需要为 1 的位置,去和存储的内容进行比对,如果 1 的位置完全匹配,那么就为 “存在”,如果有一个位置为 0 , 就为 “不存在”,但是有些时候,如果 2个不同元素的 所有 1 的位置都相同,那么就会出现 “误报”
还有一个需要注意的地方是, 布隆过滤器不会误判那些 “已经见过的元素”,它只会误判那些没见过的元素。
也就是说误判会出现在,如果你给它一个没见过的元素,看看它是不是以为自己见过了
要降低 error_rate,就需要更大的存储空间,默认的 error_rate 是 0.01 , initial_size 是 100
如果要修改默认的参数需要调用
127.0.0.1:6379> bf.reserve students 0.001 1000
OK
127.0.0.1:6379> 
布隆过滤器的 initial_size 太大会浪费存储空间,设置过小,会影响准确率。
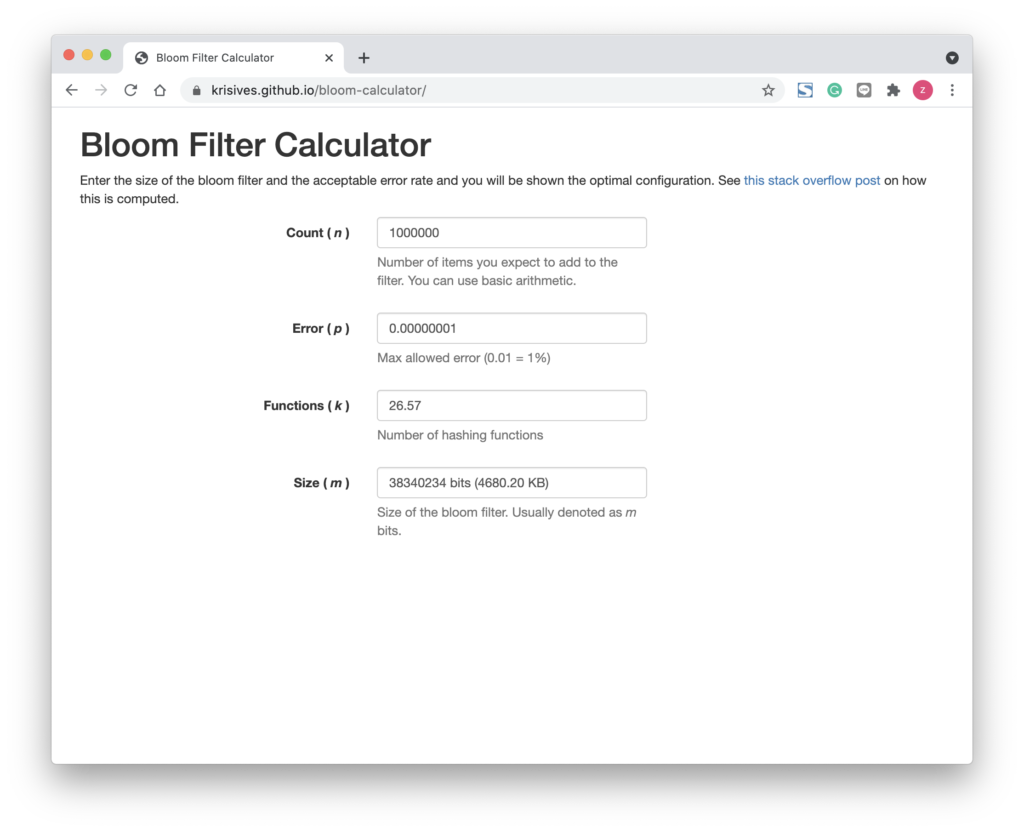
那么如何来判断布隆过滤器的空间占用呢?这里有一个简单的公式
k = hash函数的最佳数量
n = 元素数量
f = 错误率
k = 0.7 * ( 1/n )
f = 0.6185 ^ ( 1/n )
^ 次方操作, math.pow
https://krisives.github.io/bloom-calculator
HyperLogLog的一个重要作用就是 计数 + 去重, 尤其适合做 UV 统计
HyperLogLog提供不精确的计数方案,标准误差 0.81%
127.0.0.1:6379> pfadd students lizhe
(integer) 1
127.0.0.1:6379> pfadd students lizhe
(integer) 0
127.0.0.1:6379> pfadd students lizhe
(integer) 0
127.0.0.1:6379> pfadd students Jon
(integer) 1
127.0.0.1:6379> pfadd students Jon
(integer) 0
127.0.0.1:6379> pfcount students
(integer) 2
127.0.0.1:6379>分布式锁实际上就是 synchronized 关键字,在同一时间,只能有一个线程,进入当前 同步 代码块 (修改数据)
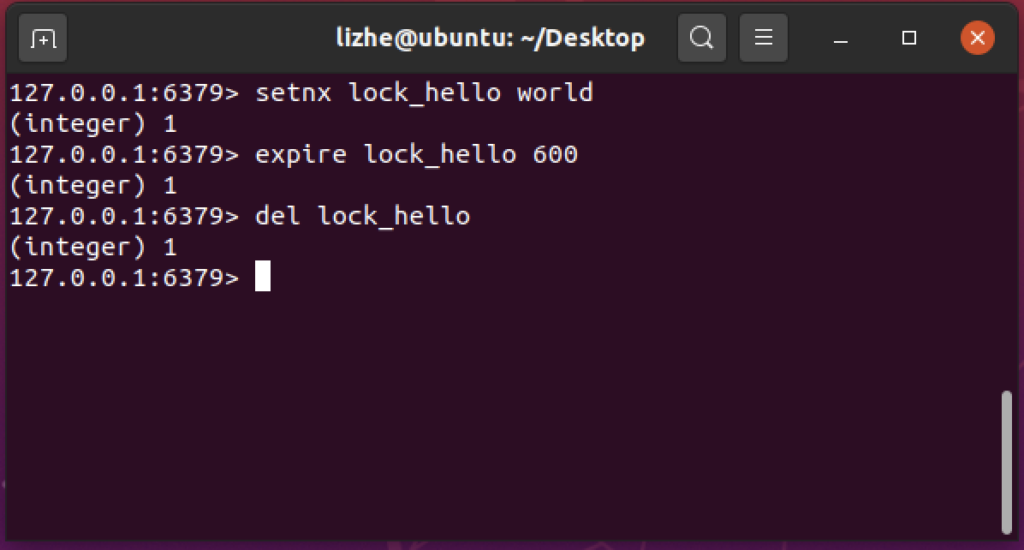
在 redis 中一般使用 setnx (set if not exists) 指令实现,通常会搭配 del 和 TTL 使用
如果 setnx 返回 1 ,证明当前无人占用,为了避免 del 之前发生异常,导致没有正确删除,会使用 TTL 设置过期时间
当锁存在时 (已经被人占用)
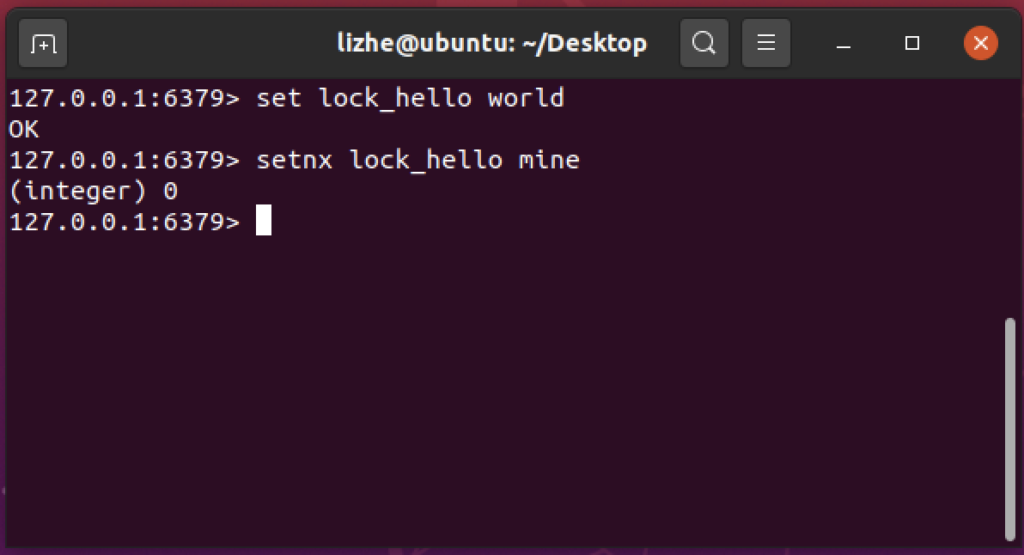
可是如果 expire 指令也没有得到正确执行呢?
Redis 2.8 版本中加入了一个 可以将 set 和 expire 合并的 原子操作
set lock_hello world ex 600 nx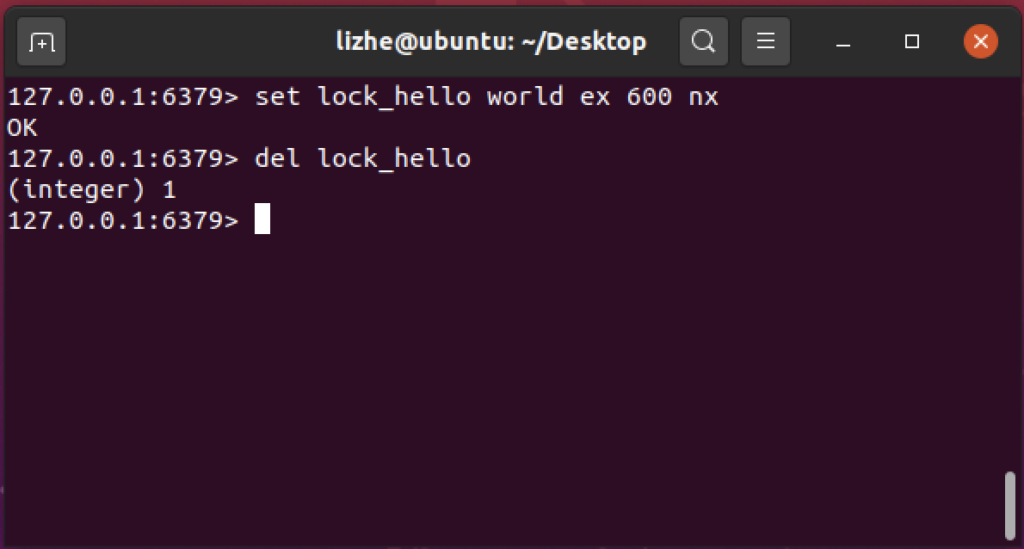
如果没有抢到 锁 , 会得到一个 nil
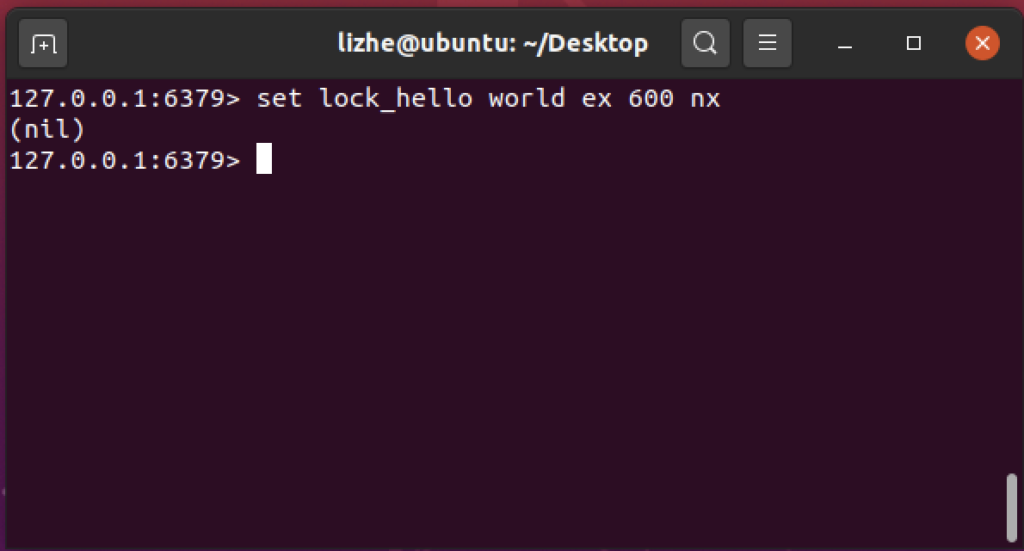
如果逻辑代码的执行时间特别的长,而且不稳定,那对于锁的 TTL 就要慎重考虑
例如:
这里有两个问题
对于第二个问题可以通过将 local_key 的 value 值 设置成 随机数 来解决
张三 放入 随机数 5323 , 李四的 setnx 并不会改变这个值 (设置如果不存在),那么李四在del之前需要比较这个值是否与自己 setnx 的值一致,来决定是否删除这个值,这样每个 锁 都只能由 创建者 删除,或者 TTL 超时由系统删除
Redis 是 Remote Dictionary Service 远程字典服务的首字母缩写
Redis 的 5 种数据结构分别为 string、list、hash、set 和 zset 也就是 字符串、列表、字典、结合 和 有序集合
Redis 所有的数据结构都以唯一的 key 字符串作为名称,然后通过这个唯一的 key 来获取相应的 value 数据。
不同类型的数据结构的差异就在于 value 的结构不一样。
字符串内部是一个字符数组,类似Java的ArrayList,小于 1M 大小的空间时是全增的,直接 double 一倍容量,超过1M 大小时,每次增加 1M,最大 512M
虽然可以使用 set age 30 来存储 数字,而且可以使用 incr age 来使它自增,但是 数字实际上也是 string
2 列表
Redis 的 list 相当于Java的 LinkedList,是一种链表 而不是 数组。插入 和 删除 非常快 O(1),但是索引定位很慢 O(n),列表的每个元素都使用双向指针顺序,可以同时支持向前向后遍历。
在列表元素较少的情况下,会使用一块连续内存,这个结构是 ziplist,将所有的元素彼此紧挨着一起存储。当数据量较多的时候会改成普通链表,所以redis将列表和ziplist结合起来组成了 quicklist,也就是将 多个 ziplist 使用双向链表串起来使用。
3 hash字典
类似Java的HashMap是一种无序字典, 数组 + 链表 的 二维结构,第一维的 hash 数组位置碰撞时,就会将碰撞的元素使用链表串起来
Redis的字典值只能是 字符串
另外 java 的 hashmap 在 rehash 的时候需要阻塞,redis为了高性能不阻塞,采用的是渐进式rehash策略。
4 set集合
Redis 的集合 相当于 Java的 HashSet,内部是 无序键值对,并且是 唯一的。
它的内部实现是一个 所有value值都为 NULL的特殊字典。Set结构天生自带去重功能。
5 zset 有序列表
zset 类似 java 的 SortedSet 和 HashMap 的结合体,一方面它是一个set保证了value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。
zset 的内部实现使用的是一种叫做 跳跃列表 的数据结构
通用规则:
list、set、hash 和 zset 四种数据结构是容器类型数据结构
过期时间:
Redis 所有的数据结构都可以设置过期时间,时间到了,redis会自动删除对应的 对象。
需要注意的是,过期是以对象为单位的,如果hash结构的过期时间是整个hash对象,而不是某个key
另外,如果一个string对象设置了过期时间,然后你使用set方法修改了它,但是没有指定新的过期时间,它的过期时间会消失