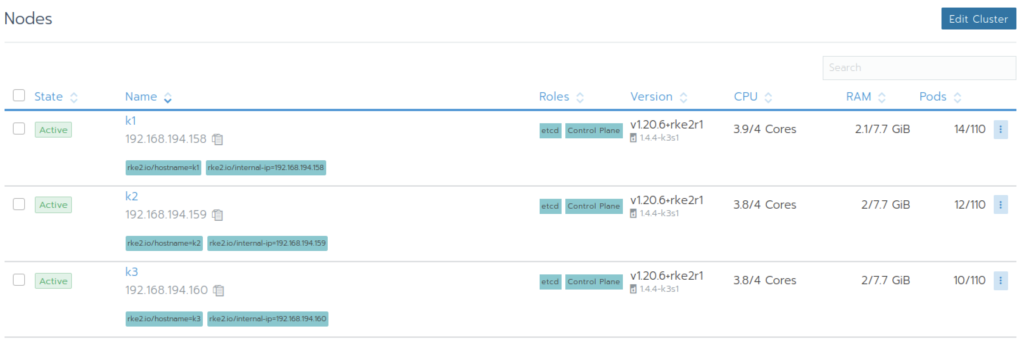
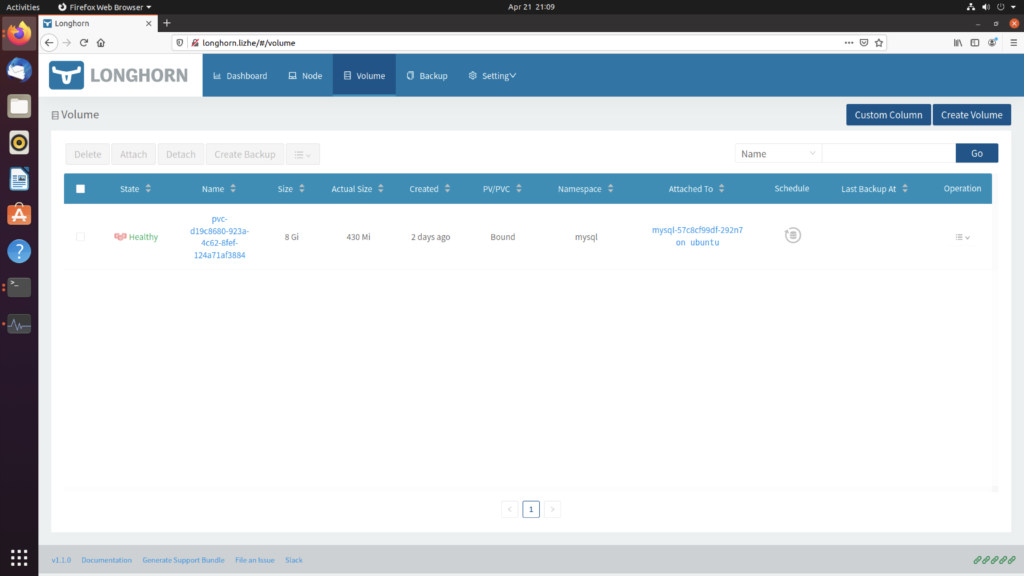
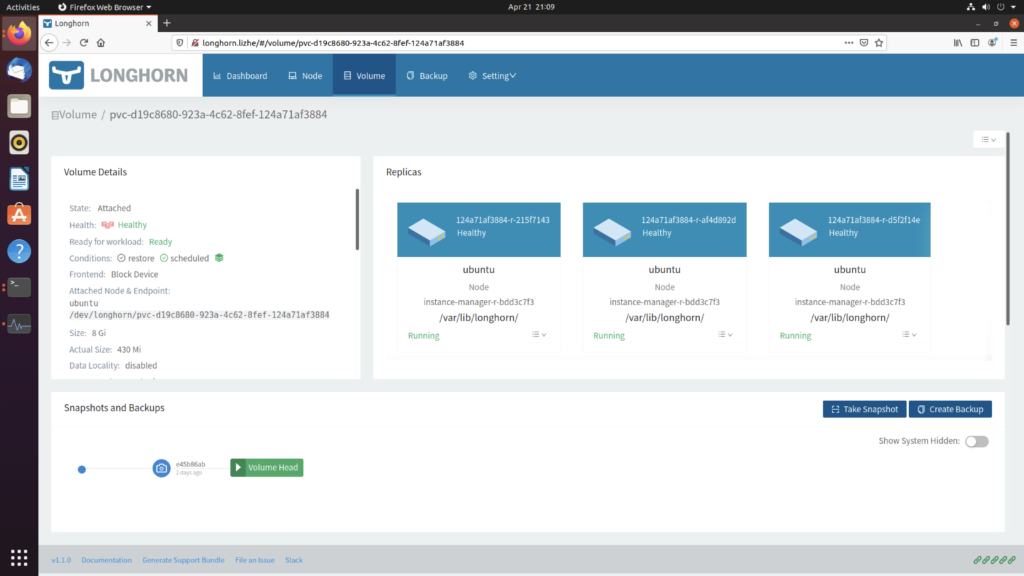
Kubelet 和 CRI
Kubelet的核心功能是在宿主机上创建Pod,并启动它所定义的各个容器。
在Kubernetes社区中,Kubelet 和 CRI 都属于 SIG-Node。
Kubernetes 有两个不可替代的组件,一个是kube-apiserver 另一个就是 Kubelet。
Kubelet本身是按照 控制器模式 来工作的。工作核心是一个控制循环 SyncLoop
驱动该控制循环运行的事件包括四种
- Pod 更新事件
- Pod 生命周期变化
- Kubelet 本身设置的执行周期
- 定时清理事件
Kubelet会通过Watch机制,监听与自己相关的Pod对象的变化。当然,这个watch的过滤条件是该Pod的nodeName字段与自己的相同。Kubelet会把这些Pod的信息缓存在自己的内存中。
这里需要注意的是,kubelet 调用下层容器运行时的执行过程并不会直接调用Docker的API,而是通过一组叫做CRI的gRPC接口来间接执行的。在1.6 版本之前的Kubernetes,是直接调用Docker API来创建和管理容器的
CRI机制的核心就在于每种容器项目现在都可以自己实现一个CRI shim,自行对CRI请求进行处理。这样,Kubernetes就有了一个统一的容器抽象层。
除了dockershim之外,其他容器运行时的CRI shim 都需要额外部署在宿主机上。
CNCF中的 containerd 项目就可以提供一个典型的 CRI shim 能力,把Kubernetes发出的CRI请求转换成对 containerd的调用,然后创建出runC容器。而runC项目才是负责执行设置容器 Namespace、Cgroups 和 chroot 等基础操作的组件。
CRI 里还有一组叫做 RunPodSandbox接口。它对应的并不是Kubernetes 里的Pod API 对象,而只是抽取了 Pod 里的一部分与容器运行时相关的字段,如 HostName、DnsConfig、CgroupParent 等。
作为具体的容器项目,你需要自己决定如何使用这些字段来实现一个Kubernetes期望的Pod模型。
当执行了 kubectl run创建了一个包含 A、B两个容器的Pod之后,这个Pod的信息最后来到kubelet。
然后kubelet会按照一下步骤创建 A、B两个容器
- RunPodSandbox(foo)
- CreatContainer(A)
- StartContainer(A)
- CreatContainer(B)
- StartContainer(B)
在具体的CRI shim中,这些接口的实现可以完全不同
如果是Docker项目,dockershim就会创建出一个名为 foo 的 Infra容器 (pause容器),用来 hold 整个Pod的Network Namespace。
如果是基于虚拟化技术的容器,比如 Kata Containers项目,它的CRI实现就会直接创建出一个轻量级的虚拟机来充当Pod
在RunPodSandbox 接口实现中,还需要调用 networkPlugin.SetUpPod(…)来为这个Sandbox设置网络。这个SetUpPod(…)就是执行CNI插件里的add(…)方法。
所以最后在宿主机上,dockershim会留下3个容器,Kata Containers 则会留下一个轻量级虚拟机。
如果对一个容器调用 kubectl exec , 这个请求会先交给 api server,然后api server会调用 kubelet的exec api,这样kubelet就会调用CRI 的 exec 接口,而负责响应这个接口的是 CRI shim。
CRI shim会返回一个此CRI shim的 streaming server 的地址和端口 URL 给kubelet,kubelet拿到URL之后,会以 redirect的方式返回给 api server,api server 就会通过重定向来向 streaming server 发起真正的 exec 请求,并与它建立长连接。