Kiali安装
先去加一个 helm仓库
https://charts.helm.sh/stable/
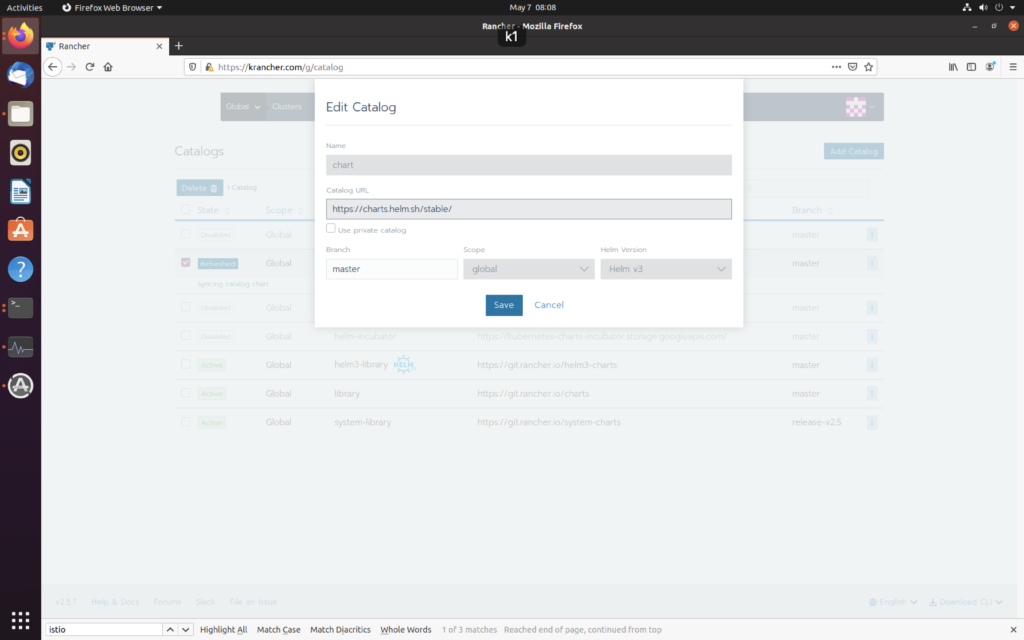
然后发现竟然。。。没有
所以只好去找官网
https://istio.io/latest/docs/ops/integrations/kiali/
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.9/samples/addons/kiali.yaml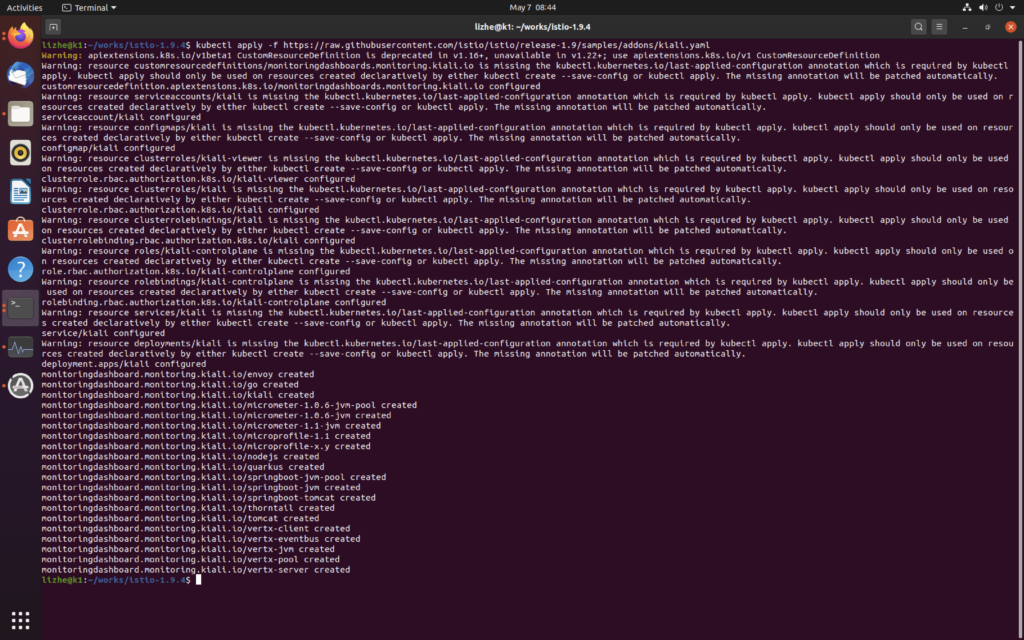
然后
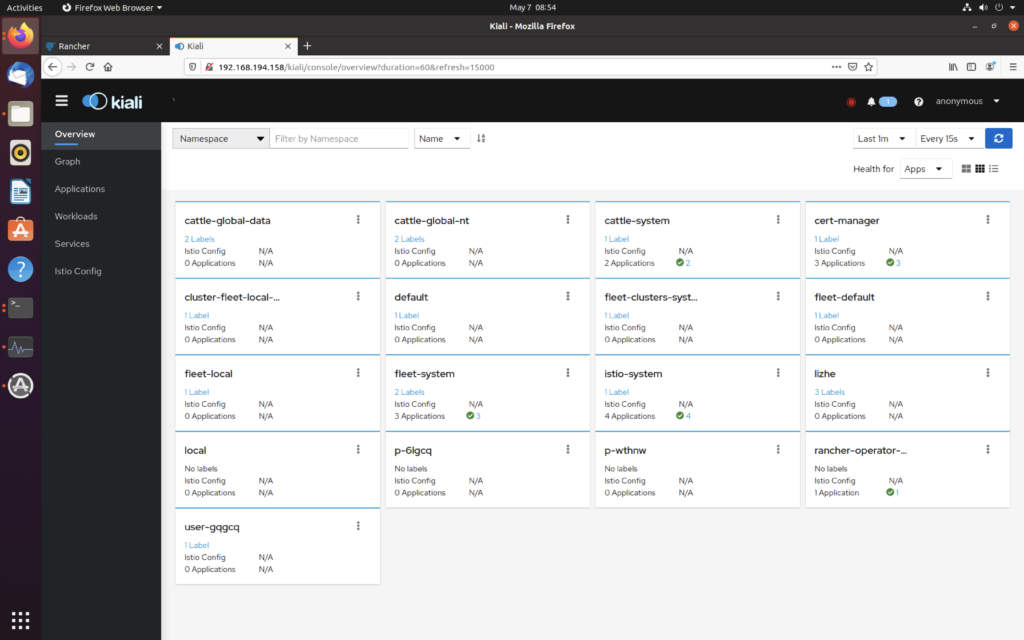
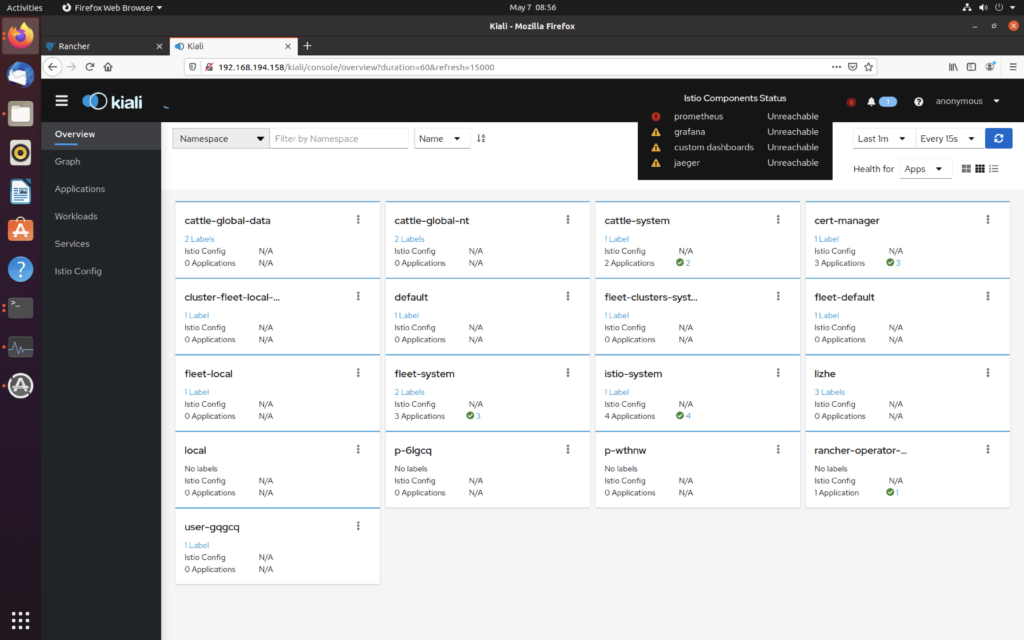
仔细看上面有个错误
先去加一个 helm仓库
https://charts.helm.sh/stable/
然后发现竟然。。。没有
所以只好去找官网
https://istio.io/latest/docs/ops/integrations/kiali/
kubectl apply -f https://raw.githubusercontent.com/istio/istio/release-1.9/samples/addons/kiali.yaml然后
仔细看上面有个错误
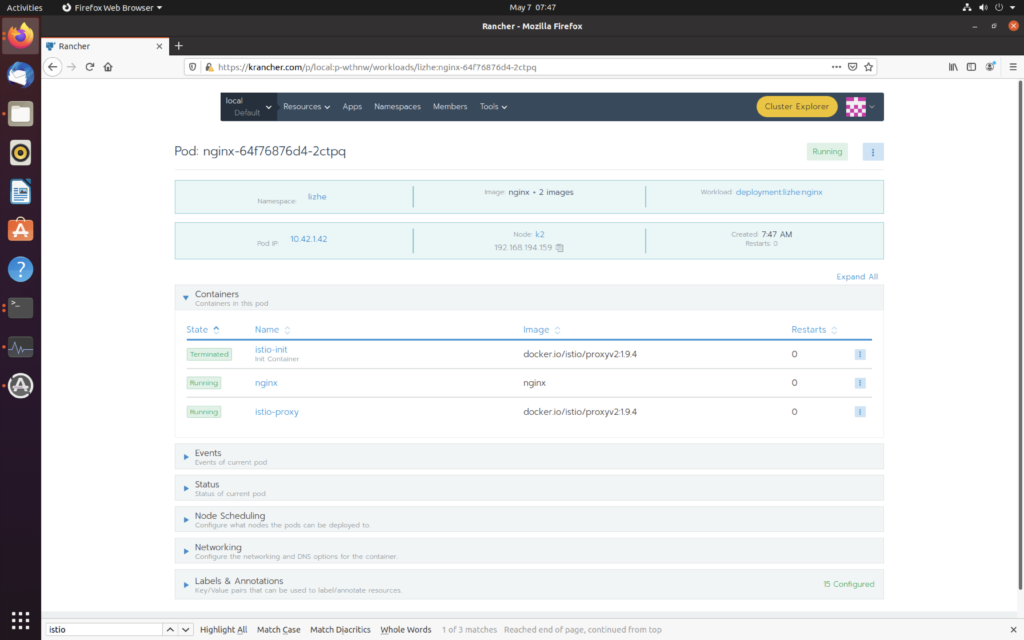
为命名空间设置标签 istio-injection=enabled 就能自动注入
kubectl label namespace lizhe istio-injection=enabled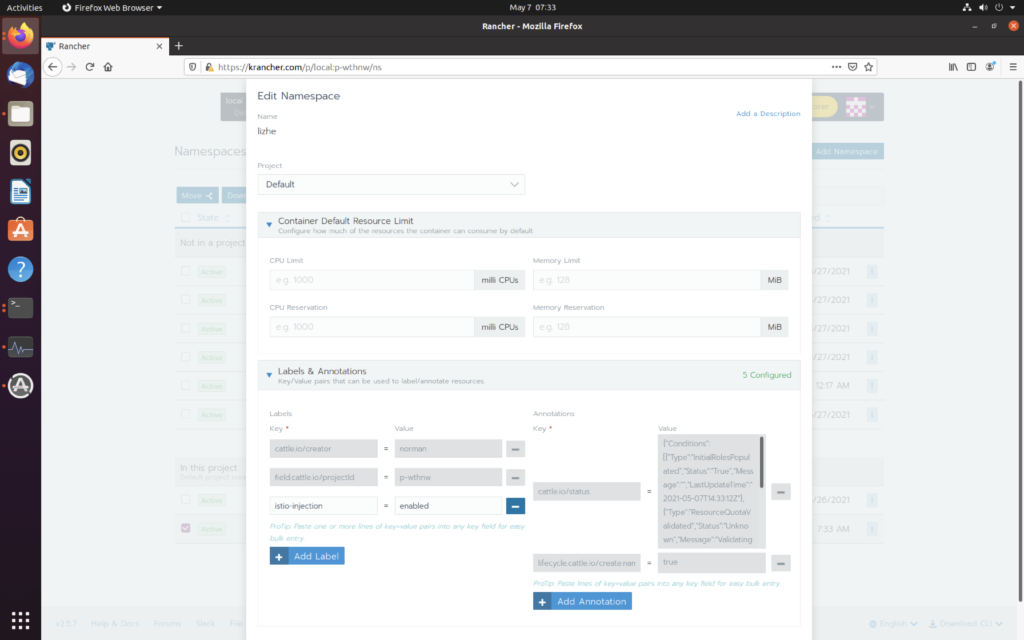
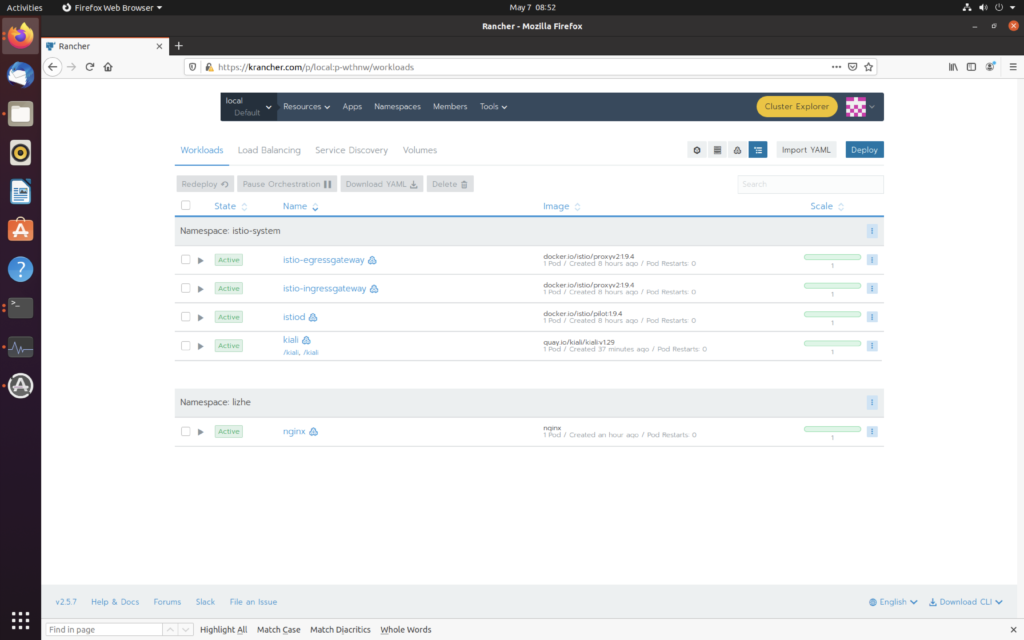
然后就可以看到 namespace 下有 小帆船了
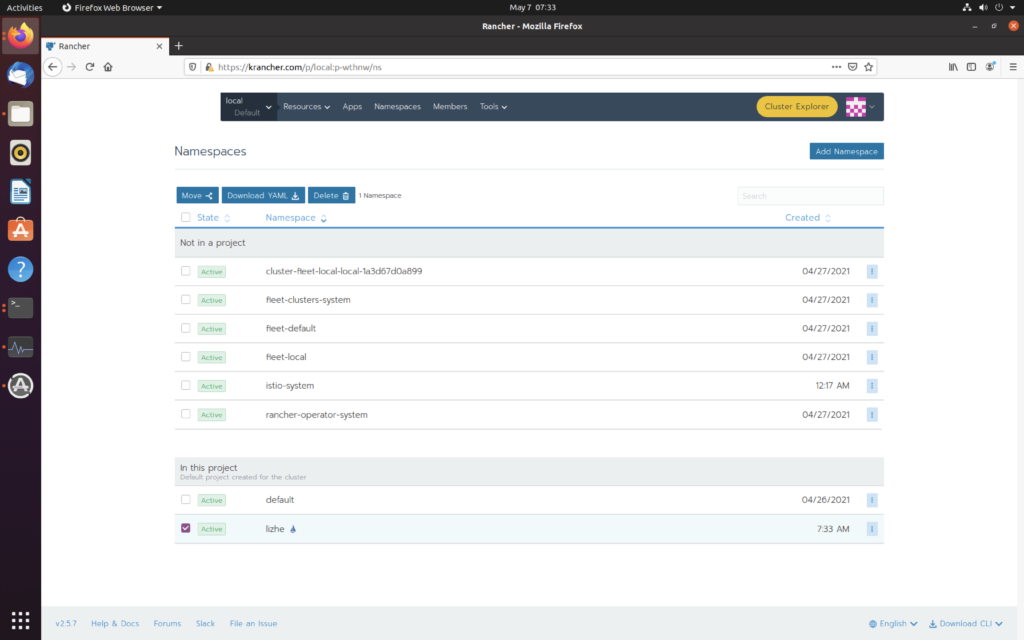
然后在这个namespace下部署一个 nginx,可以看到已经注入了
下载
curl -L https://istio.io/downloadIstio | sh -确保自己在解压之后的目录

创建namespace
kubectl create namespace istio-system安装 istio base chat
helm install istio-base manifests/charts/base -n istio-system
安装 istio discovery chat 它用于部署 istiod 服务
helm install istiod manifests/charts/istio-control/istio-discovery \
--set global.hub="docker.io/istio" \
--set global.tag="1.9.4" \
-n istio-system
安装 istio ingress
helm install istio-ingress manifests/charts/gateways/istio-ingress \
--set global.hub="docker.io/istio" \
--set global.tag="1.9.4" \
-n istio-system安装 istio egress
helm install istio-egress manifests/charts/gateways/istio-egress \
--set global.hub="docker.io/istio" \
--set global.tag="1.9.4" \
-n istio-system
验证安装
kubectl get pods -n istio-systemetcd v3.0.0 于 2016年6月30日正式发布,标志着该版本正式稳定。
etcd v3 版本保留了 v2 的协议和api,所以v2和v3是共存的(用URL)区分,也就是说本质上,v2和v3是两个共享同一套raft协议代码的两个独立应用,它们的api不同,存储不同 甚至数据也是相互隔离的
如果从 v2 升级到 v3 那么原来 v2 的数据还是只能用 v2 的 api 来访问, 通过 v3 创建的数据也只能通过 v3 来访问
etcd v3.2 or before uses only [CLIENT-URL]/v3alpha/.
etcd v3.3 uses [CLIENT-URL]/v3beta/ while keeping [CLIENT-URL]/v3alpha/.
etcd v3.4 uses [CLIENT-URL]/v3/ while keeping [CLIENT-URL]/v3beta/. [CLIENT-URL]/v3alpha/ is deprecated.
etcd v3.5 or later uses only [CLIENT-URL]/v3/. [CLIENT-URL]/v3beta/ is deprecated.
例如 3.2 版本下

这里的 key 和 value 都必须是 base64的
echo "foo" | base64
echo "Zm9vCg==" | base64 -d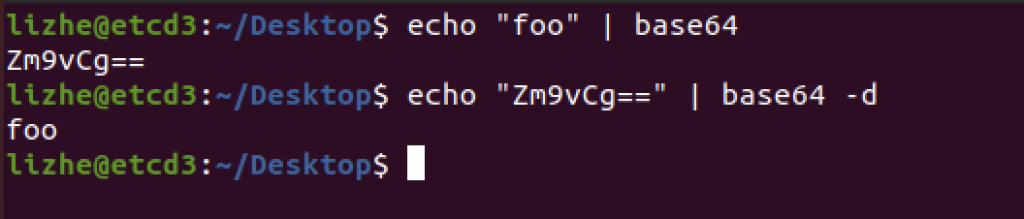
watch机制
curl -N http://localhost:2379/v3alpha/watch -X POST -d '{"create_request": {"key":"Zm9vCg=="} }' &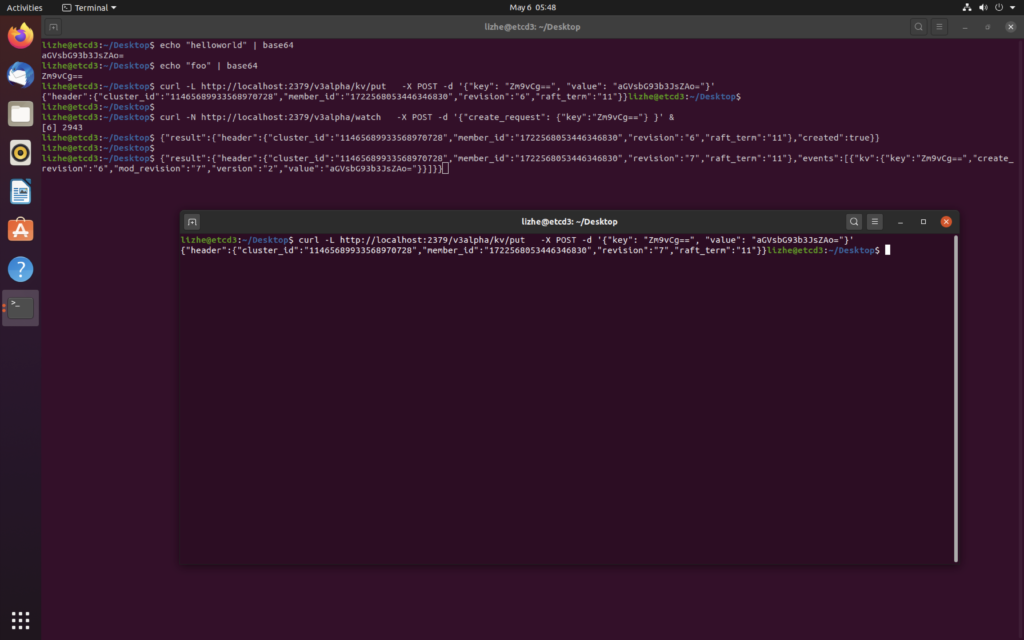
v3 的 watch 和 v2 还有一个很大不同就是,它默认就是长效watch,不再需要添加 stream=true
Etcd 默认使用 2380 端口监听其他server的请求,2379 则用来提供 HTTP API 服务
docker run --restart=always --net host -it --name etcd1 -d -v /var/etcd:/var/etcd -v /etc/localtime:/etc/localtime registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.2.24 etcd --name etcd-s1 --auto-compaction-retention=1 --max-request-bytes=33554432 --quota-backend-bytes=8589934592 --data-dir=/var/etcd/etcd-data --listen-client-urls http://0.0.0.0:2379 --listen-peer-urls http://0.0.0.0:2380 --initial-advertise-peer-urls http://192.168.194.164:2380 --advertise-client-urls http://192.168.194.164:2379,http://192.168.194.164:2380 --initial-cluster-token etcd-cluster --initial-cluster "etcd-s1=http://192.168.194.164:2380,etcd-s2=http://192.168.194.165:2380,etcd-s3=http://192.168.194.166:2380" --initial-cluster-state newdocker run --restart=always --net host -it --name etcd2 -d -v /var/etcd:/var/etcd -v /etc/localtime:/etc/localtime registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.2.24 etcd --name etcd-s2 --auto-compaction-retention=1 --max-request-bytes=33554432 --quota-backend-bytes=8589934592 --data-dir=/var/etcd/etcd-data --listen-client-urls http://0.0.0.0:2379 --listen-peer-urls http://0.0.0.0:2380 --initial-advertise-peer-urls http://192.168.194.165:2380 --advertise-client-urls http://192.168.194.165:2379,http://192.168.194.165:2380 --initial-cluster-token etcd-cluster --initial-cluster "etcd-s1=http://192.168.194.164:2380,etcd-s2=http://192.168.194.165:2380,etcd-s3=http://192.168.194.166:2380" --initial-cluster-state newdocker run --restart=always --net host -it --name etcd3 -d -v /var/etcd:/var/etcd -v /etc/localtime:/etc/localtime registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.2.24 etcd --name etcd-s3 --auto-compaction-retention=1 --max-request-bytes=33554432 --quota-backend-bytes=8589934592 --data-dir=/var/etcd/etcd-data --listen-client-urls http://0.0.0.0:2379 --listen-peer-urls http://0.0.0.0:2380 --initial-advertise-peer-urls http://192.168.194.166:2380 --advertise-client-urls http://192.168.194.166:2379,http://192.168.194.166:2380 --initial-cluster-token etcd-cluster --initial-cluster "etcd-s1=http://192.168.194.164:2380,etcd-s2=http://192.168.194.165:2380,etcd-s3=http://192.168.194.166:2380" --initial-cluster-state new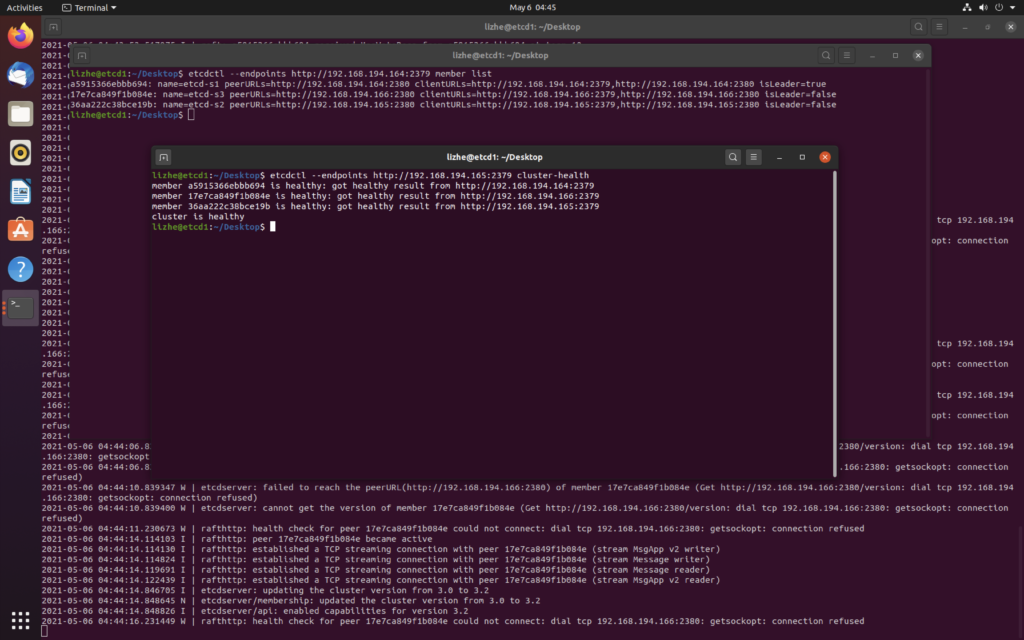
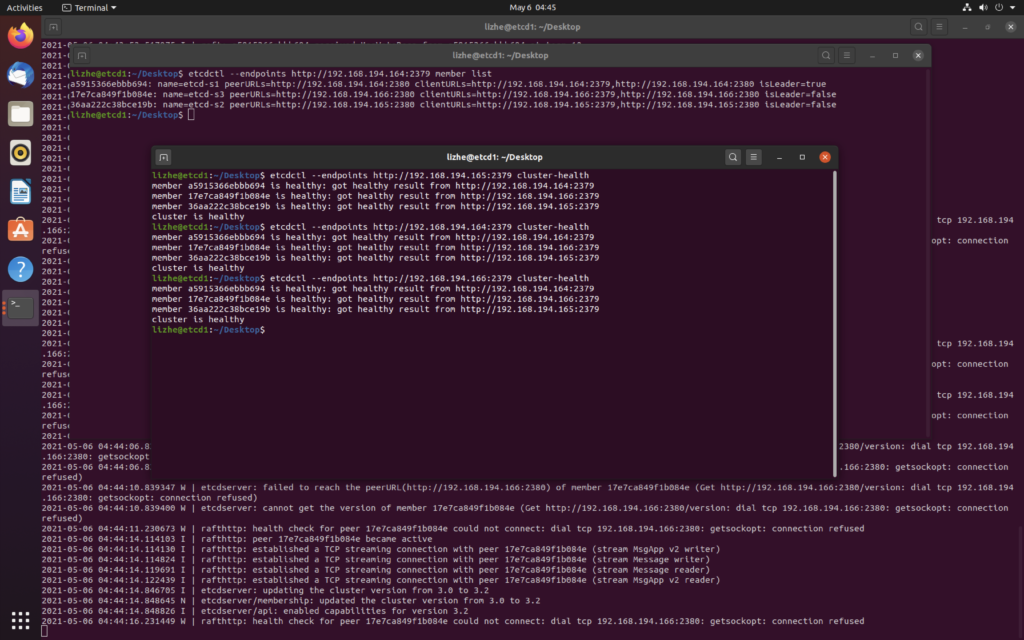
Etcd 读和写都可以保证线性一致
线性一致性读需要在所有节点走一遍确认,查询速度会有所降低,要开启线性一致性读,在不同的 client是有所区别的:
为了保证线性一致性读,早期的 etcd(_etcd v3.0 _)对所有的读写请求都会走一遍 Raft 协议来满足强一致性。然而通常在现实使用中,读请求占了 etcd 所有请求中的绝大部分,如果每次读请求都要走一遍 raft 协议落盘,etcd 性能将非常差。
因此在 etcd v3.1 版本中优化了读请求(PR#6275),使用的方法满足一个简单的策略:每次读操作时记录此时集群的 commit index,当状态机的 apply index 大于或者等于 commit index 时即可返回数据。由于此时状态机已经把读请求所要读的 commit index 对应的日志进行了 apply 操作,符合线性一致读的要求,便可返回此时读到的结果。
综上所述,当 超半数节点宕机时,由于无法 apply ,也就没法进行读取动作
raft 算法主要使用两种方式来提高可理解性
raft协议组织的集群中,一共包含3类角色
raft 算法将时间划分成为任意个不同长度的任期,任期是单调递增的,用连续的数字 1、2、3 … 表示。
每一个任期,都是由一次选举人选举开始的。
每个任期只能选举出一个领导人,如果选票被平分,那么本次选举失败,系统会直接进入下一任期
每一个raft节点各自都在本地维护一个当前任期值,增加这个数字以进入下一任期
主要有两种场景:开始选举 和 与其他节点交换信息
当节点进行通信时,会相互交换当前的任期号。如果一个节点的当前任期号比其他节点的任期号小,则将自己本地的任期号自觉地更新为较大的任期号。如果一个候选人或领导人意识到自己的任期号过时了(比别人小),那么它会立刻切换回群众状态,如果一个节点收到的 拉票请求 锁携带的任期号是过时的,那么该节点就会拒绝本次拉票请求。
领导人选举
raft 通过选举一个权力至高无上的领导人,并采取赋予它管理复制日志权力的方式来维护节点间日志的一致性。领导人从客户端接收日志条目,再把日志条目复制到其他服务器上,并且在保证安全的前提下,告诉其他服务器将日志条目应用它们的状态机中。
每个候选人携带一个 “造反计时器”,并且每个选举人的计时器时间是随机的,各不相同。
领导人会定时向各个节点发送 “不要造反心跳”,各节点接收到 “不要造反心跳” 后,会重置自己的 “造反计时器”,为了避免频繁地发生选举,Leader广播心跳的周期会小于 “造反计时器” (选举定时器)的超时时间。
如果一个Follower决定参加选举,那么它会执行以下步骤
然后它可能会得到以下结果
日志复制
一旦某个领导人赢得了选举,那么它就会开始接受客户端的请求。
客户端请求都将被解析成一条需要复制状态机执行的指令。领导人节点把这条指令作为一个新的日志条目加入它的日志文件中,然后并行地向其他raft节点发起 AppendEntries RPC,要求其他节点复制这个日志条目。
过半数节点复制成功之后,领导人节点会发起 apply 指令将这条日志应用到它的状态机中,并向客户端返回,然后再向其他节点广播应用消息。
这里因为 Follower 节点会无条件的服从 Leader,如果Leader在响应了客户端请求之后(日志已经分发,但是还没有apply)发生了故障,那么新当选的 leader 和 之前的leader 数据可能发生冲突。所以在raft中有一个重要限制, 任何领导人都必须拥有之前任期提交的全部日志条目
raft采用拉票的方式来保证这一机制,当候选人进行拉票时,投票人会检查候选人提交的最新日志条目是否大于等于自己本地的条目,如果候选人的条目没有比自己的日志条目更新,那么选举人将拒绝此次投票请求。比较的依据是日志文件中最后一个条目的索引和任期号
首先用docker来启动etcd
docker run -d\
-p 2379:2379 \
-p 2380:2380 \
--name etcd quay.io/coreos/etcd:latest \
/usr/local/bin/etcd \
--data-dir=/etcd-data --name node1 --listen-client-urls http://0.0.0.0:2379 --advertise-client-urls http://0.0.0.0:2379 --listen-peer-urls=http://0.0.0.0:2380 --initial-advertise-peer-urls=http://0.0.0.0:2380
我们往etcd里加入一个键值对
curl http://127.0.0.1:2379/v2/keys/key1 -XPUT -d value="Hello world"
etcd 的 watch 监听分为两种,一次性监听 和 持续监听
监听到了事件则返回json数据。返回后监听退出,后续需要再次启动监听。recursive为监听所有子节点变化。
curl http://127.0.0.1:2379/v2/keys/key1?wait=true&recursive=true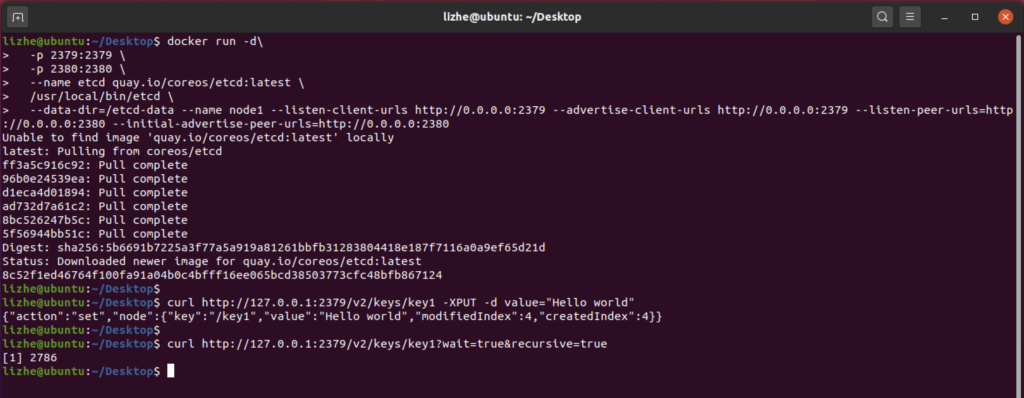
然后我们来改变这个key1的值
curl http://127.0.0.1:2379/v2/keys/key1 -XPUT -d value="changed value"当key1的值变化后,可以看到 之前wait的进程结束了,并且监听到了返回
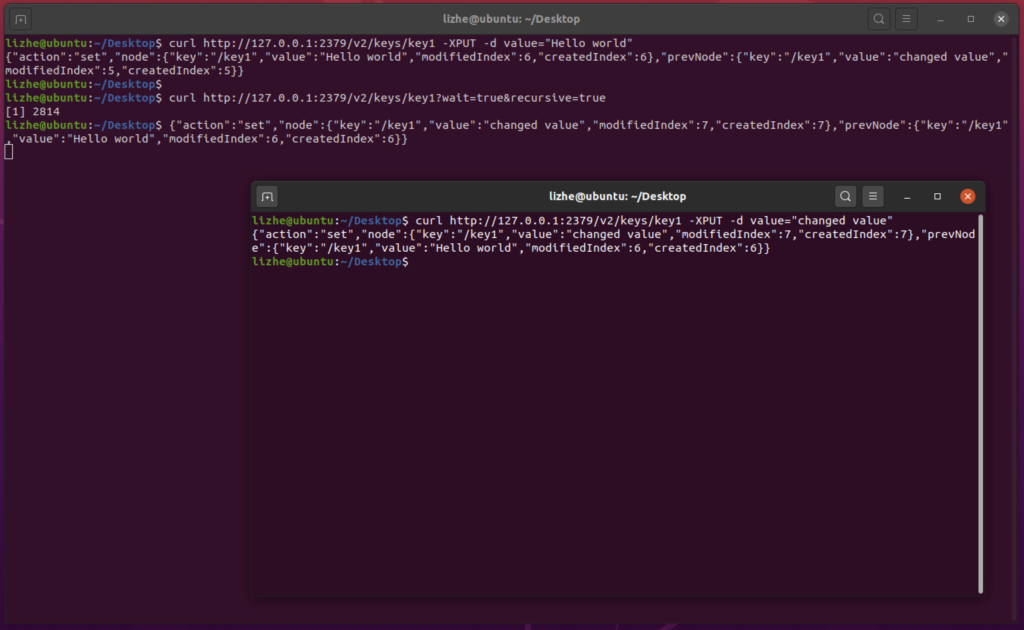
永久监听,监听到了事件不会退出,持续返回数据。相比一次性监听要可靠
curl http://127.0.0.1:2379/v2/keys/key1\?wait\=true\&recursive\=true\&stream\=true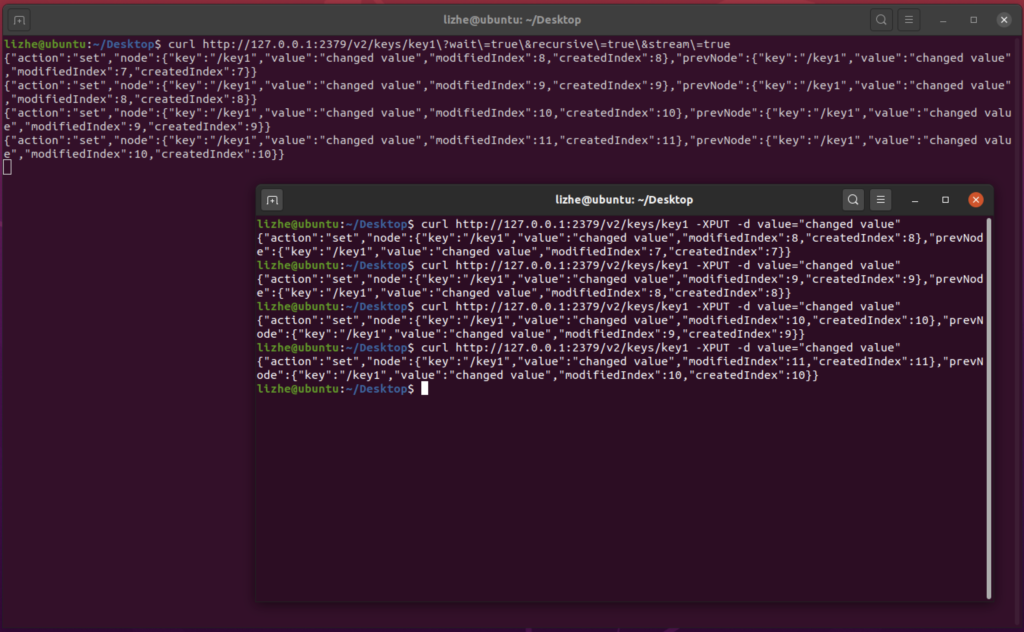
这里我使用的是 Longhorn 作为 PV,实际上S3也是一个不错的选择

选择 rancher backups
安装以后把默认存储改成 Storage Class

Rancher backups 会创建一个对应的PVC
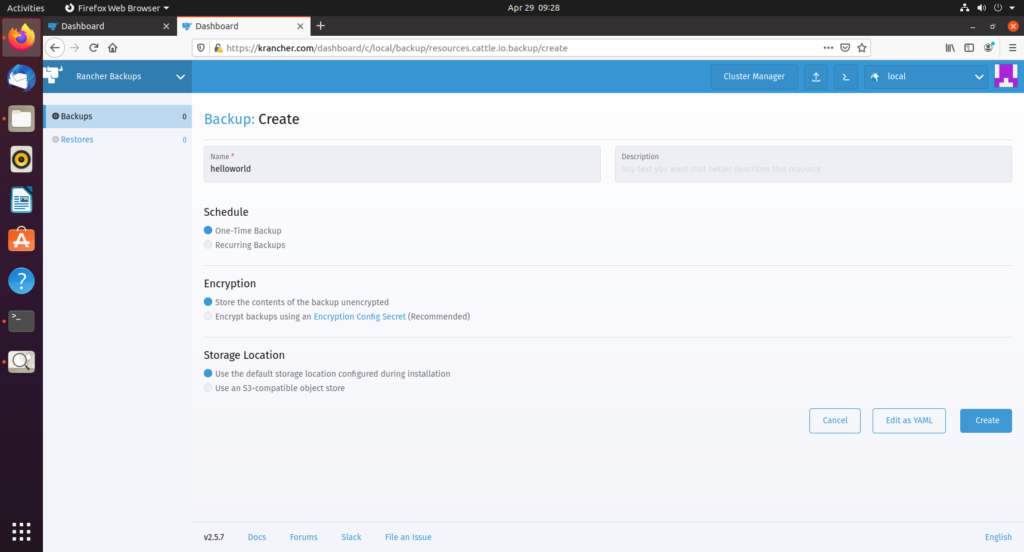
选择创建备份
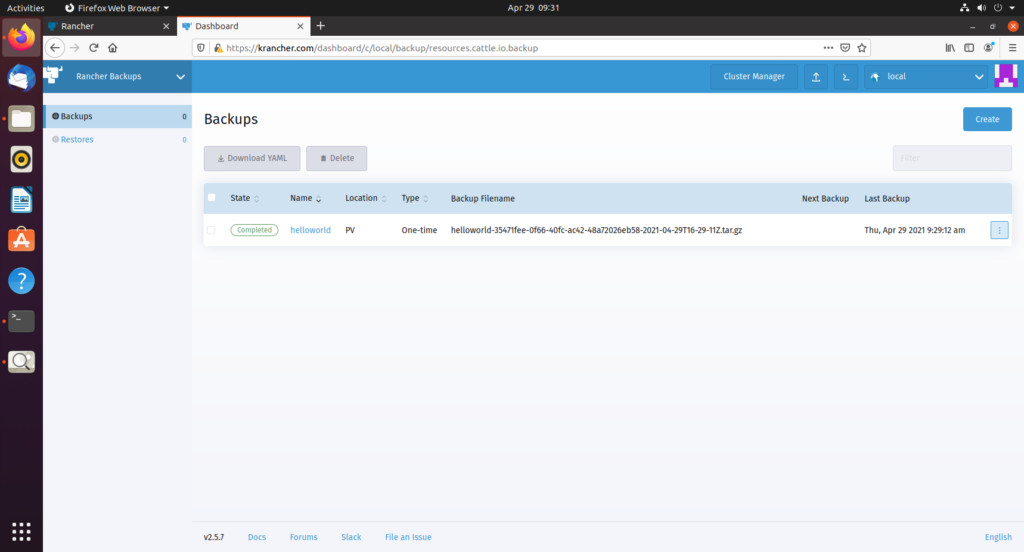
在 Longhorn 中查看

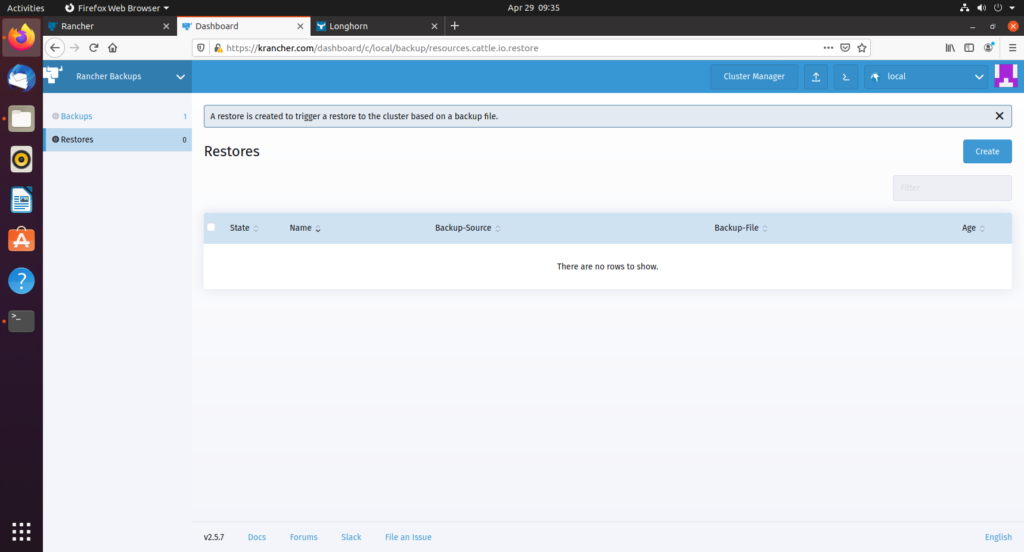
使用backup还原
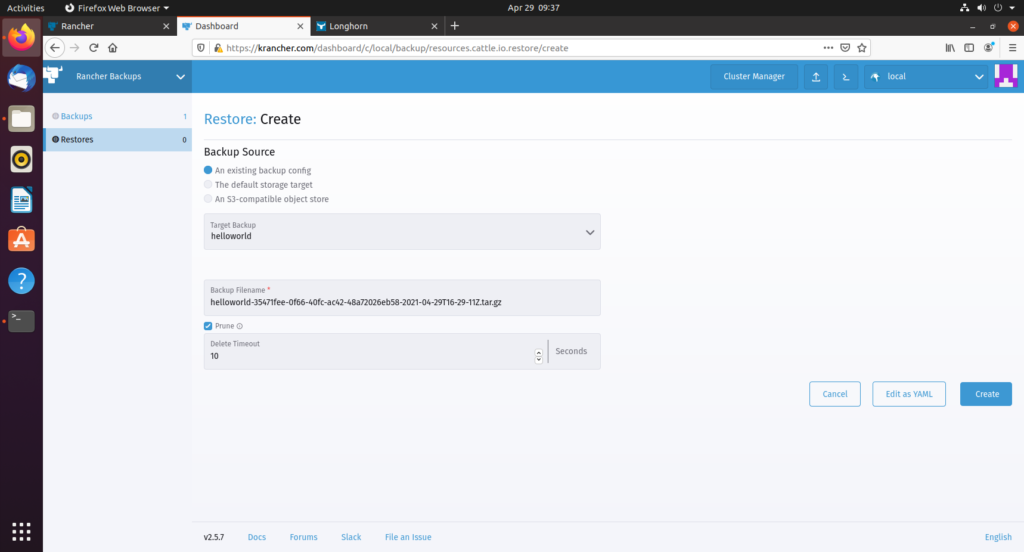
等待上面截图中 restore 状态从 active 变为 Completed
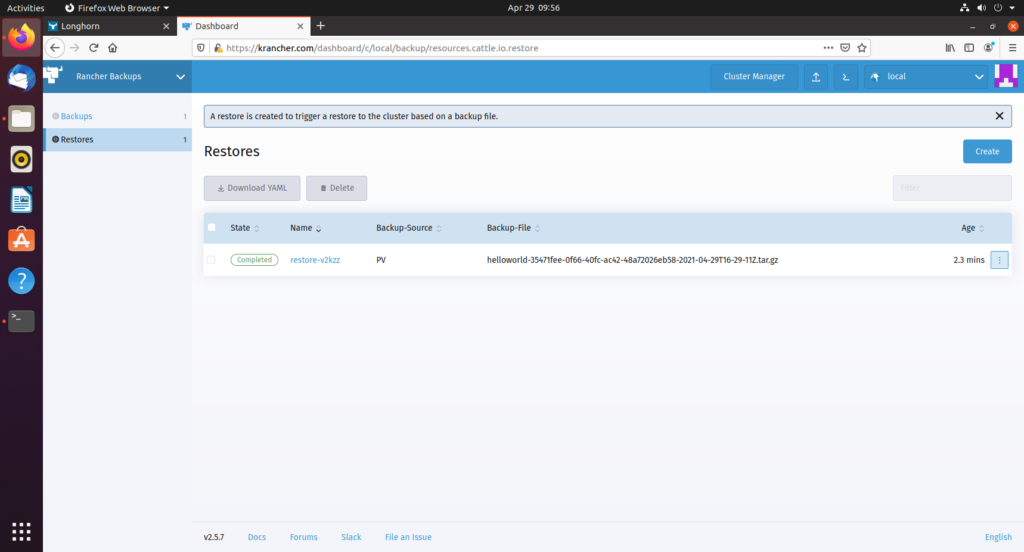
rancher backup 会还原以下3种资源
默认的备份存储路径是
/var/lib/rancher/rke2/server/db/snapshots

默认的etcd数据保存在
/var/lib/rancher/rke2/server/db/etcd

第一种情况,如果要直接使用 /var/lib/rancher/rke2/server/db/etcd 中的原数据,然后把 集群节点 缩减到 只剩一台 server 节点,可以直接使用 reset 命令
systemctl stop rke2-server
rke2 server --cluster-reset第二种情况,想使用备份还原
rke2 server \
--cluster-reset \
--cluster-reset-restore-path=<PATH-TO-SNAPSHOT>此命令会生成一个文件 /var/lib/rancher/rke2/server/db/etc/reset-file,如果想要再次reset,需要删除这个文件