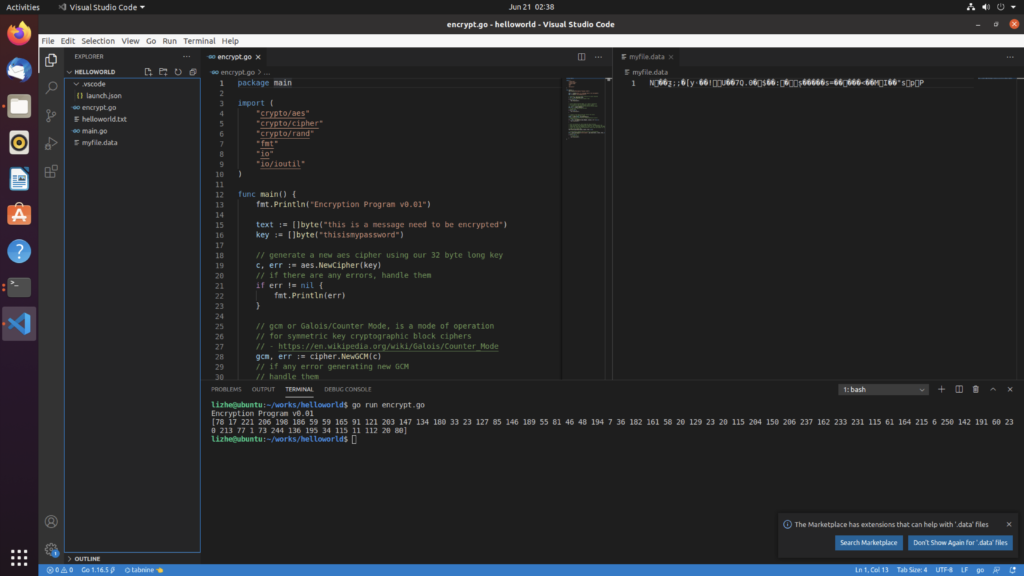
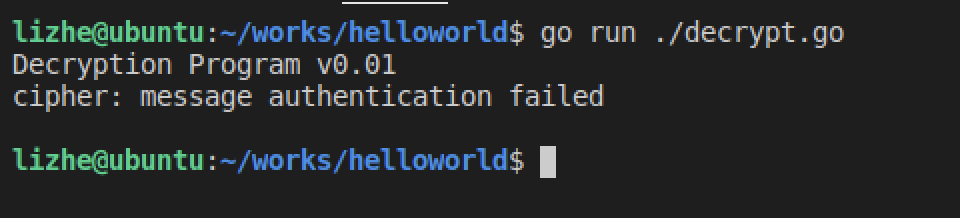
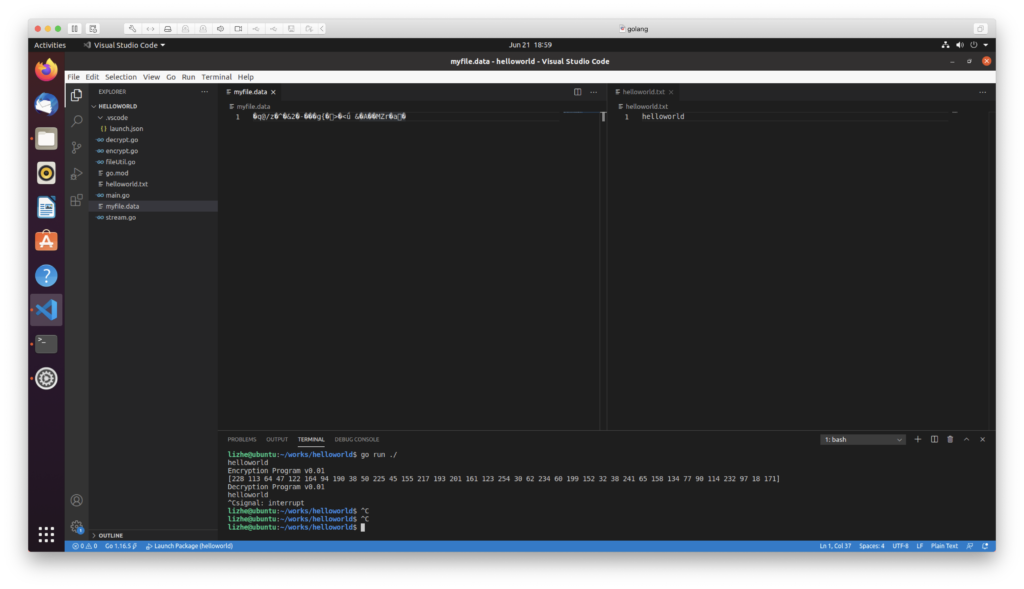
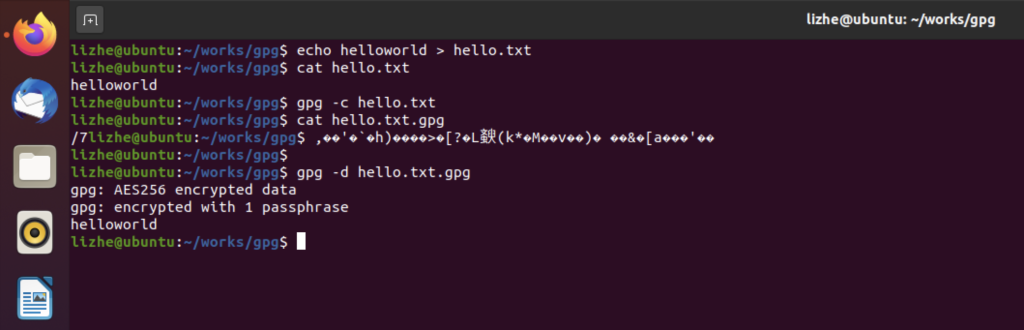
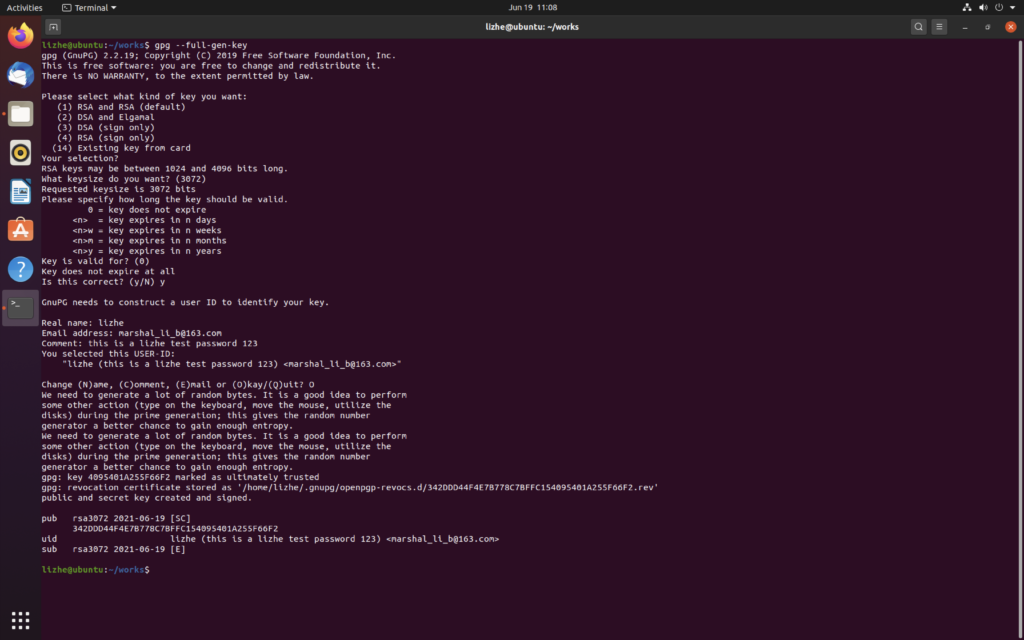
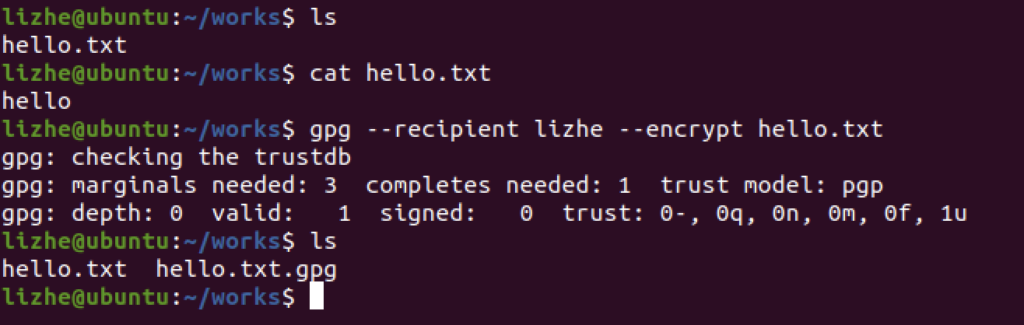
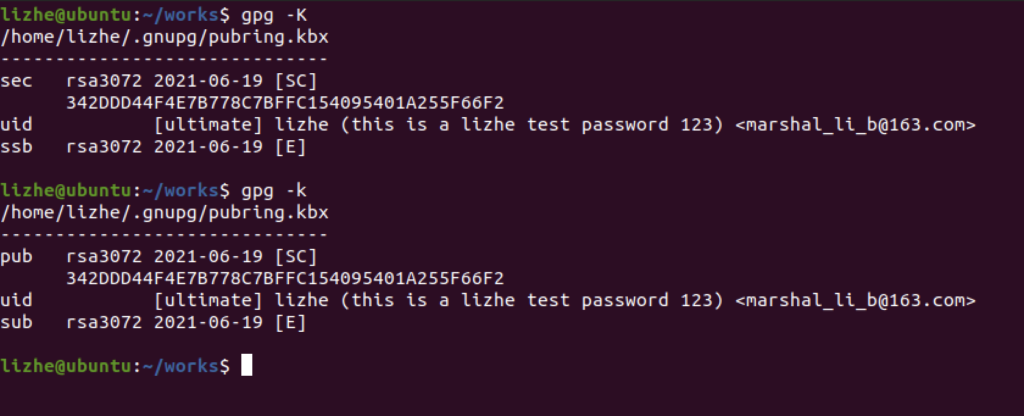
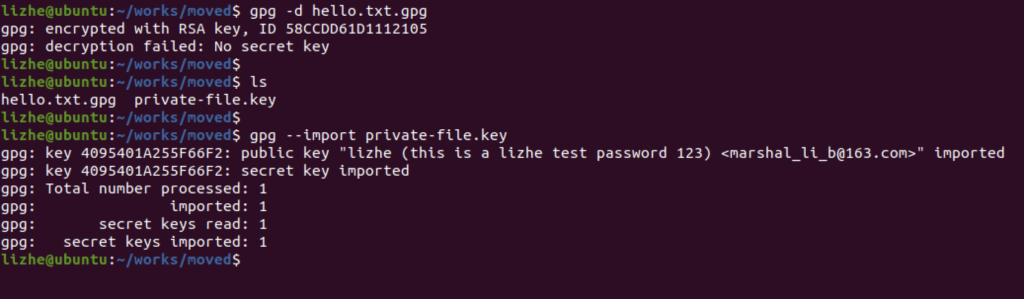
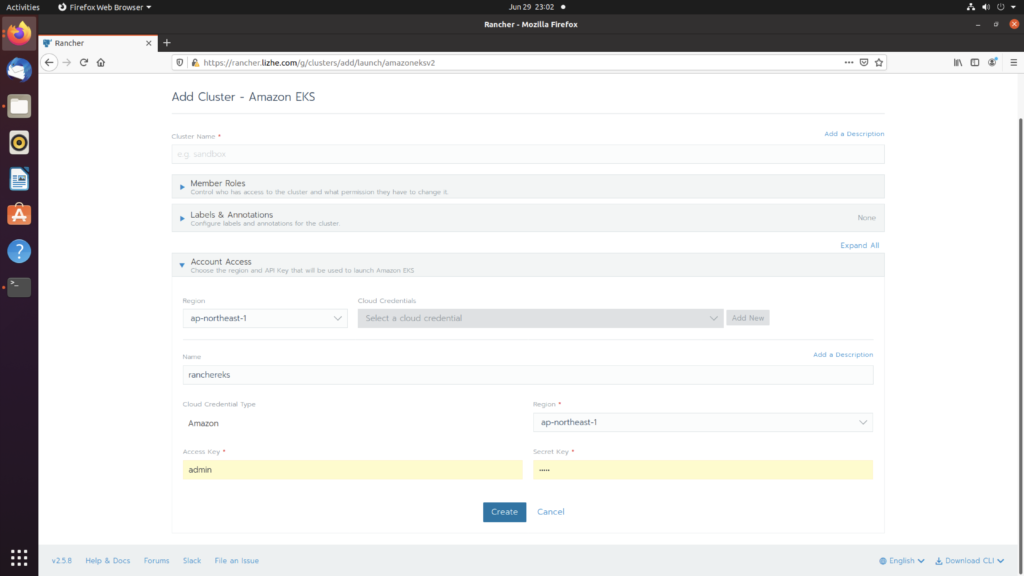
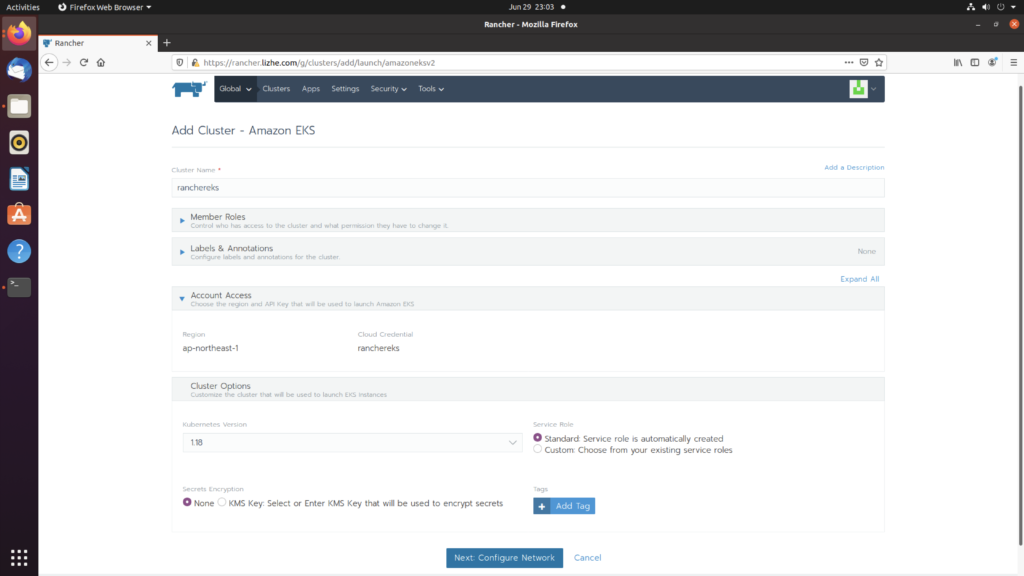
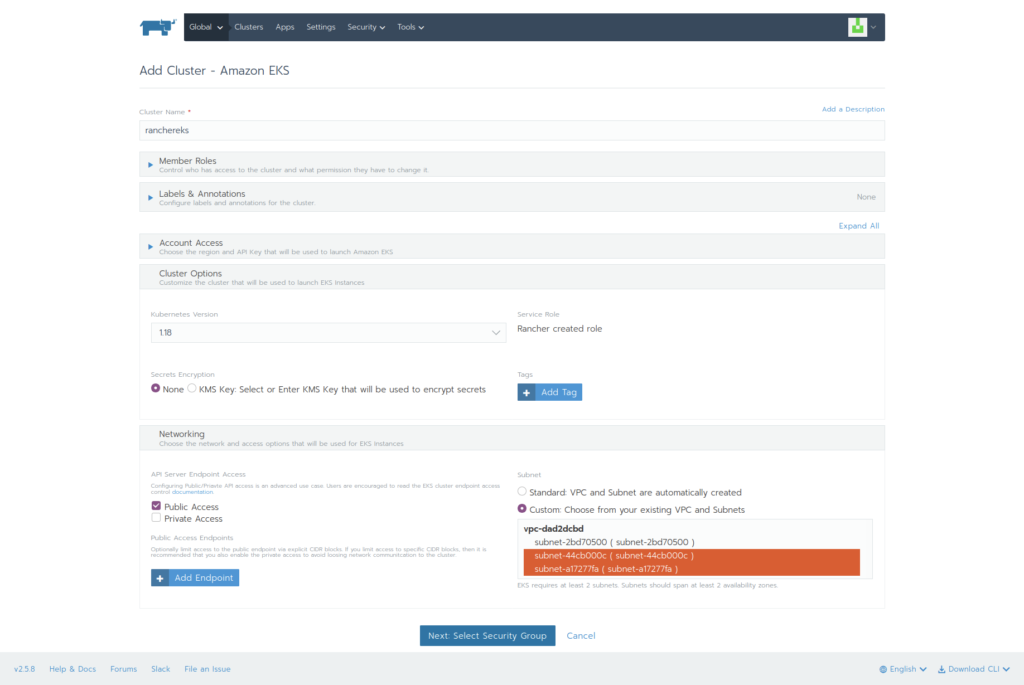
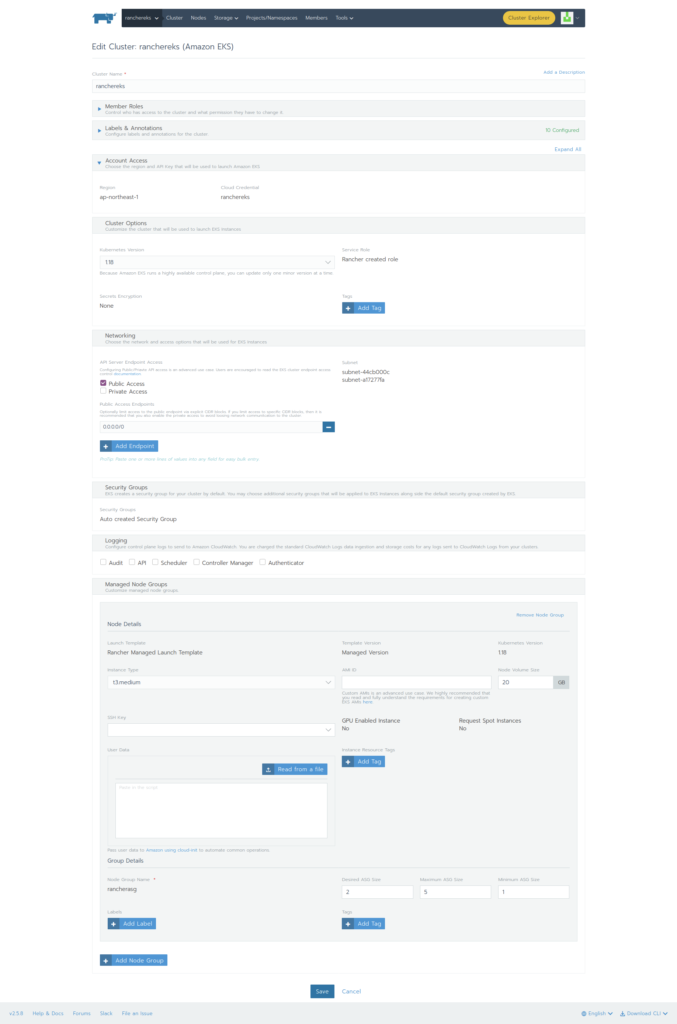
Elasticsearch 提供了专门的 _validate REST 端点来验证查询,并且不会真正的执行它们。
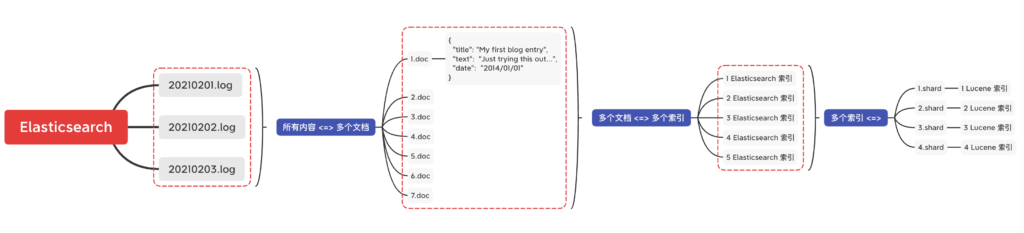
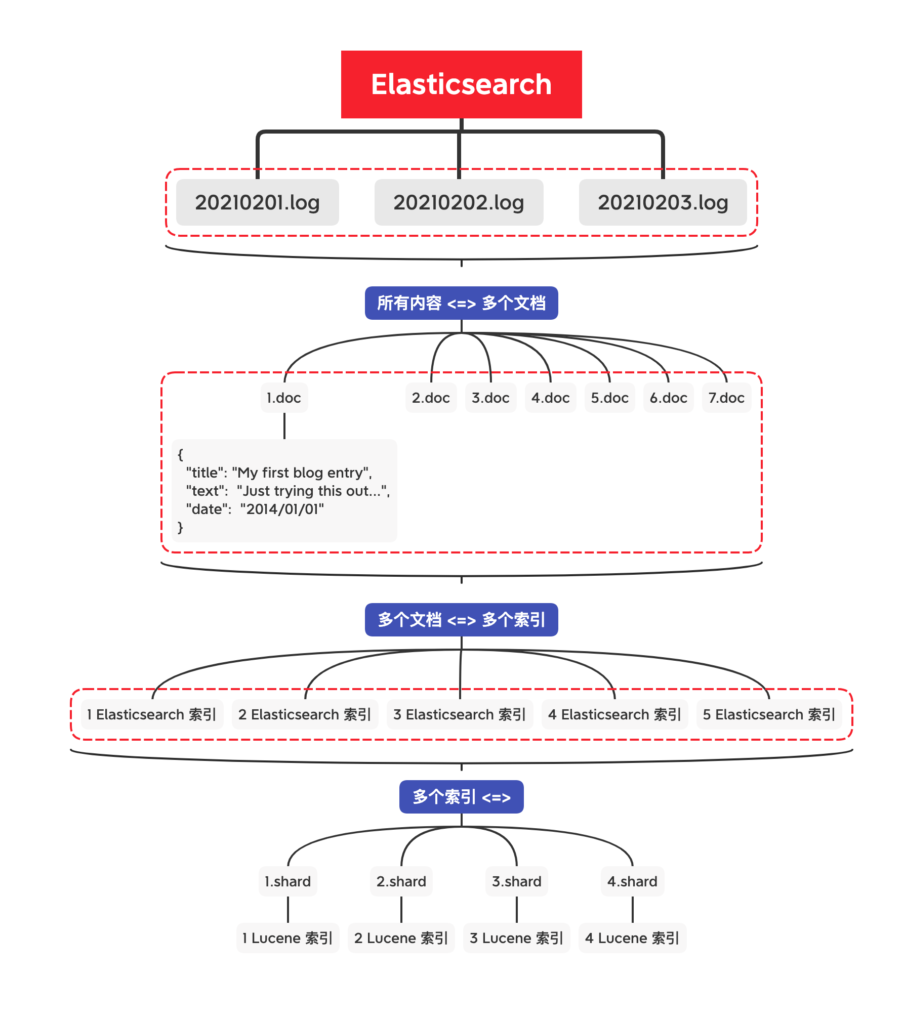
获得详细查询执行报告的查询分析器
通过 Profile �API 用户可以了解查询请求在底层是怎样执行的
profile.shard.id 响应中包含的每个分片的唯一 ID
"profile" : {
"shards" : [
{
"id" : "[esdfsdfgdfghsdf-40jfQ][.apm-agent-configuration][0]",
"searches" : [
{
"query" : [
{
"type" : "MatchNoDocsQuery",
"description" : """MatchNoDocsQuery("unmapped fields [org]")""",
"time_in_nanos" : 1229,
profile.shard.searches 包含查询执行详细信息的数组
profile.shard.rewrite_time 一次完整的查询改写过程所花费的总时间,单位是 纳秒
profile.shard.collector 这一部分是关于运行查询的 Lucene 收集器的内容
Lucene的工作实际上是定义一个收集器,负责协调对所匹配文档的遍历、评分和收集。收集器的内容也包括一个查询如何记录聚合结果、执行全局查询、执行查询后的过滤器等。
热点线程
通过使用
/_nodes/hot_threads 或者 /_nodes/{nodeornodes}/hot_threads 端点
http://172.16.184.194:9200/_nodes/hot_threads
自动创建副本
Elasticsearch 允许在集群足够大时自动扩展副本
index.auto_expand_replicas 0-all
冗余和高可用
Elasticsearch 的副本机制不仅可以处理更高的查询吞吐量,同时也给了冗余和高可用。
防止分片及其副本部署在同一个节点上
elasticsearch.yml 文件中设置如下
node.attr.server_name: server1
另外再添加
cluster.routing.allocation.awareness.attributes: server_name
这告诉 Elasticsearch 不要把主分片 和 它的副本放到具有相同 node.attr.server_name 属性的节点上
集群节点角色
Elasticsearch 在任意给定时间只需要一个主节点,如果有3个master节点,通过设置
discovery.zen.minimum_master_nodes: 2
可以防止脑裂
ELasticsearch 优化的一般建议
索引刷新频率
索引刷新频率是指 文档需要多长时间才能出现在结果中
规则非常简单:刷新率越高,查询越慢,且索引文档的吞吐量月底
刷新率默认是 1秒,这基本上意味着索引查询器每隔1秒重新打开一次
刷新率为 1秒 时,使用一个Elasticsearch节点大概每秒能够索引 1000份文档。
刷新率为 5秒 时,索引吞吐量可以提升 25%,大概每秒 1280 份文档
刷新率为 25秒 时,索引量可以提升超过 70%,大概每秒 1700份文档
无限制地增加刷新时间是没有意义的,因为超过某一定值(取决于负载和数据量)之后,性能提升将变得微乎其微。
线程池调优
只有遇到
节点的队列已经被填满,并且仍有计算能力剩余,而且这些算力可以被用于处理等待的作业
时,才需要考虑调整默认的线程池配置
数据分布
Elasticsearch 的每个索引都可以被分成多个分片,并且每个分片都有多个副本。
当有若干个 Elasticsearch节点,并且索引被分割成多个分片时,数据的平均分布对于平衡集群的负载就是十分重要的了,不要让某些节点做了比其他节点多太多的工作。
节点查询缓存和分片查询缓存
第一个有助于查询性能的缓存是 节点查询缓存
Elasticsearch 的节点查询缓存会在一个节点上的全部索引间共享,可以使用
indices.queries.cache.size
属性来控制缓存的大小
它表示在给定节点上能够被节点查询缓存使用的全部内存数量,默认是 10%
如果查询已经使用了过滤器,就应该监控缓存的大小和逐出。
如果看到了过多的逐出,那么缓存可能太小了,应该考虑增加缓存的大小。
缓存过小可能会对查询的性能造成负面影响
第二个缓存是分片查询缓存
分片缓存的目的是 缓存 聚合、建议器 和 命中数 (它不会缓存返回的文档,因此,只在查询的size=0时起作用)
当查询使用了聚合或者建议时,最好启用这个缓存(默认是关闭的)
index.requests.cache.enable:true
请记住如果不使用聚合或者建议器,那么使用分片查询缓存就毫无意义
常见的聚合一般是 max min sum avg
分片查询缓存默认使用的内存量,默认不会超过分配给 Elasticsearch 节点的 JVM 堆栈的 1%。
indices.requests.cache.size
要修改默认的缓存过期时间
indices.requests.cache.expire
适当使用过滤器
不使用过滤器
GET /_search
{
"query": {
"bool": {
"must": [{
"match": {
"org": "男性用"
}
}, {
"match": {
"store_code": "0696"
}
}]
}
}
}
使用 term 避免分词
GET /_search
{
"query": {
"bool": {
"must": [{
"match": {
"org": "男性用"
}
}, {
"term": {
"store_code": "0001"
}
}]
}
}
}
使用过滤器
GET /_search
{
"query": {
"bool": {
"must": [{
"match": {
"org": "男性用"
}
}],
"filter": [
{
"term": {
"store_code": "0002"
}
}
]
}
}
}
使用filter子句来引入过滤器,把绝大多数静态的、不分词的字段移动到过滤器里
这使得很容易在执行下一次查询时重用它们,并且避免对这些字段进行评分。
使用路由
如果数据支持路由,那么就应该考虑在查询的时候也使用路由
有着相同路由值的数据都会被保存到相同的分片上。
于是,可以避免在请求特定数据时查询所有的分片。
例如:如果保存客户的数据,可以使用客户 ID 作为路由。这会允许把同一客户的数据保存在同一个分片里。
在不使用路由的情况下,Elasticsearch 会先搜索全部的索引分片。
如果索引包含数十个分片,只要单个Elasticsearch 实例还能容纳得下分片的数据,使用路由对性能提升就会非常明显
不是每种情况都适合使用路由。
想要使用,首先数据需要是可分割的,这样它们才能够分布在不同的分片上。
例如,拥有十个非常小的分片 和 一个庞大的分片 是没有意义的,因为这个庞大的分片性能不会很好
将查询并行起来
通常被忘记的一件事是并行查询。
假设集群中有一个 索引,只保存在一个分片上。如果索引很大,查询性能可能比期望的要差。
如果增加副本数量不会有什么帮助,因为一个查询还是只会在索引的一个分片上执行
真正有帮助的是,把索引分割成多个分片,分片的数量取决于硬件和部署的方式
一般来说,建议把数据平均分配,于是各个节点可以有相同的负载。
例如,4个Elasticsearch节点和2个索引,可以设置成4个分片
size 和 shard_size
在处理 使用聚合的查询时,对于某些查询可以使用两个属性 size 和 shard_size
size参数定义最后的 聚合结果 返回多少组 数据
聚合最终结果的节点会从每个返回结果的分片获取靠前的结果,并且只会返回前size个结果给客户端
shard_size 参数具有相同的含义,只是它作用在分片上。 增加 shard_size 会让聚合结果更加准确(比如重点词的聚合),代价是更大的网络开销和内存使用。
降低这个参数会让聚合的结果不那么精确,但却有着网络开销小和内存使用低的好处
高索引吞吐量场景与Elasticsearch
关系到 每秒可以向Elasticsearch推送多少数据,另一些是索引相关的
批量索引的线程池 默认等于 CPU 核数,另有一个大小为 50 的请求队列
当逐个索引文档时,每秒能稳定的索引大约30份文档
以 10 为批量索引时,每秒大约能处理200份文档
掌控文档的字段
要索引的数量不同,效果也不同
文档的大小 和 对它们的解析度也同样重要
对于较大的文档,不仅能够看到索引增长,还能看到索引的速度有所减慢。
要让存储的字段尽可能的少,或者完全不要使用它们,大多数情况下,需要存储的字段只是 _source
除了 _source 字段,Elasticsearch 会默认索引 _all 字段。
_all 字段 是 ELasticsearch 用来从其他文本字段收集数据的。大多数场景下,这个字段不会被使用,因此最好关闭它。
"all_": {"enable": false}
ElasticSearch 有两个内部结构_all和_source
_all是所有字段的大杂烩,默认情况下,每个字段的内容,都会拷贝到_all字段.
这样可以忽略字段信息进行搜索,非常方便.
但是这样带来了额外的存储压力和CPU处理压力.
_source字段用于存储最初发送给elasticsearch的整个源文档。它用作搜索结果,可供检索。您无法搜索。实际上,它是在Lucene中存储的字段,未进行索引。
_all字段用于索引来自文档组成的所有字段的所有内容。您可以搜索它,但永远不要返回它,因为它已被索引但没有存储在lucene中。
_all字段成为我们所谓的倒排索引的一部分,用于为文本建立索引,并能够对其进行全文搜索,而该_source字段只是作为lucene文档的一部分存储
_source仅当您返回结果时,您才永远不会在查询中使用该字段,因为这是默认情况下Elasticsearch返回的结果
另一方面,该_all字段只是默认的“全部捕获”字段,您可以在只想搜索所有可用字段而又不想在查询中全部指定它们时使用。它很方便,但我不会在生产中过分依赖它,最好在不同的字段上运行更复杂的查询,每个字段具有不同的权重。如果您不使用它,则可能要禁用它,与_source我认为禁用它相比,其影响要小一些。
_source字段默认是存储的, 什么情况下不用保留_source字段?如果某个字段内容非常多,业务里面只需要能对该字段进行搜索,最后返回文档id,查看文档内容会再次到mysql或者hbase中取数据,把大字段的内容存在Elasticsearch中只会增大索引
调整预写日志
- ELasticsearch 有一个内部模块叫做 translog
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
这些在内存缓冲区的文档被写入到一个新的段中,且没有进行 fsync 操作。
这个段被打开,使其可被搜索。
内存缓冲区被清空。
- 每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行
所有在内存缓冲区的文档都被写入一个新的段。
缓冲区被清空。
一个提交点被写入硬盘。
文件系统缓存通过 fsync 被刷新(flush)。
老的 translog 被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
ELasticsearch 默认在事务日志中保留最多5000个操作,或者最多占用512MB空间
如果愿意付出更大的索引吞吐量,愿意付出数据在更长时间不能被索引到的代价,可以调高这些默认值
index.translog.flush_threshold_ops
index.translog.flush_threshold_size
两者都是在索引级别生效,并能通过ELasticsearch API 实时更新
一旦发生事故,对于拥有大量事务日志的节点来说,它的分片的初始化会慢一些,这是因为ELasticsearch需要在分片生效前处理完 全部的事务日志
可供索引缓存使用的内存越多,ELasticsearch 在内存中容纳的文档就越多
indices.memeory.index_buffer_size
默认会使用10%
这是设置节点的,而不是分片。
所以如果给Elasticsearch节点 分配 20GB 堆空间,并且节点上有 10个 活动分片,那么 Elasticsearch 默认会给每个分片大约 200MB