The priority and preemption mechanism solves the problem of what to do after pod scheduling fails
By default, when a pod fails to be scheduled, it will be shelved first. The scheduler will not reschedule the pod until the pod is updated or the cluster state changes.
But sometimes we want a pod with higher priority to crowd out a pod with lower priority
First, you need to submit a priorityclass definition in kubernetes
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-10000
value: 10000
globalDefault: false
description: "my desc 10000"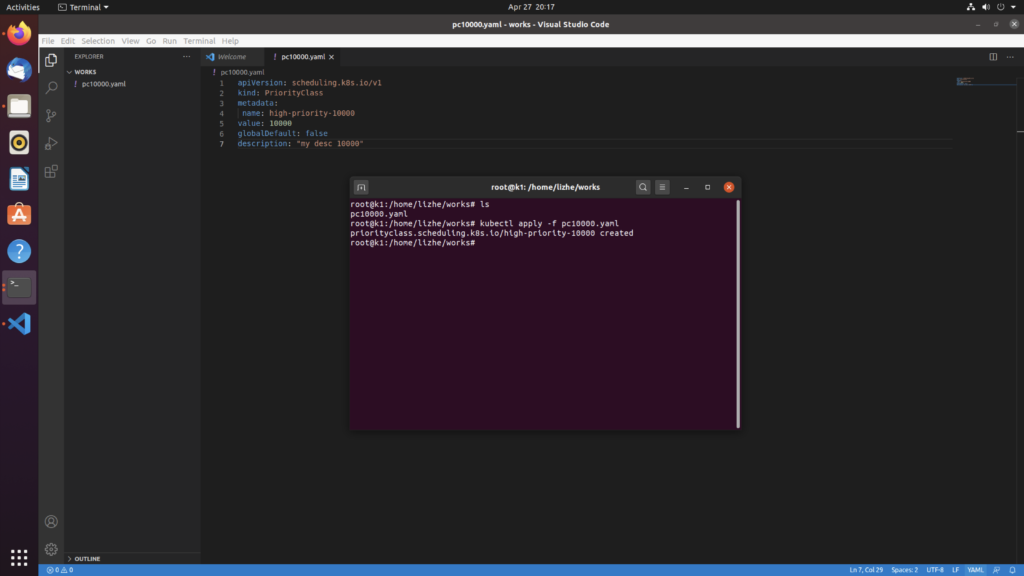
If priorityclass is not identified, its priority is 0
If you set globaldefault: false, the value of this PC will become the default value of the system
Our cluster state is 3 nodes, each with 4 cores and 8GB of memory
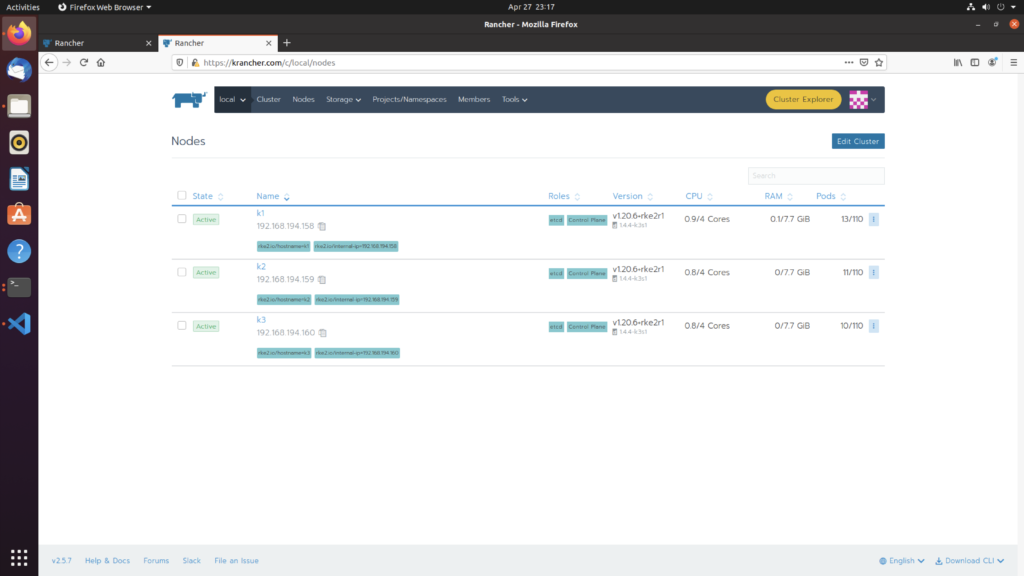
I deployed three nginx tags, each requiring three kernels
resources:
limits:
cpu: 3
memory: 2Gi
requests:
cpu: 3
memory: 2Gi
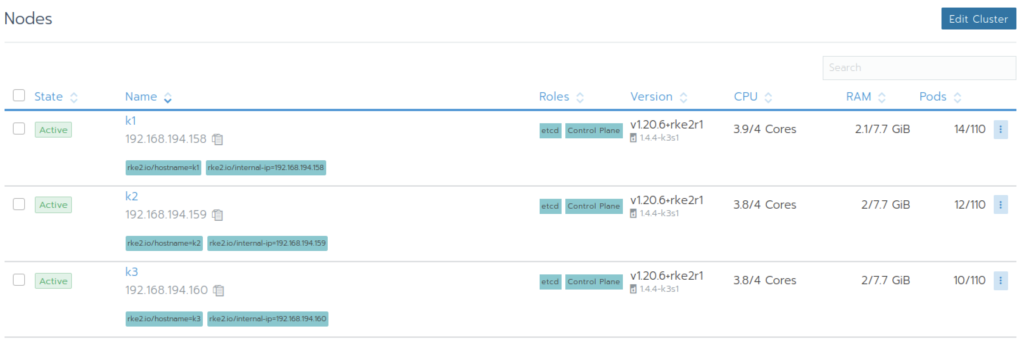
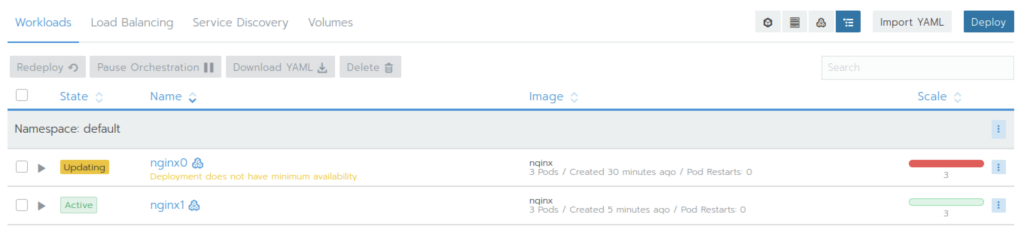
In this way, we will eat all the CPU resources
Then deploy an nginx to compete
With the same requests and the same limits, the scheduler cannot complete the scheduling without using the priority and preemption mechanism
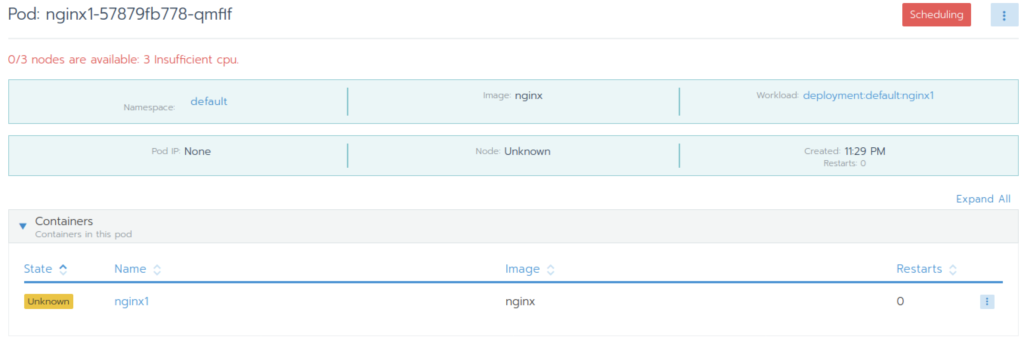
After adding priority
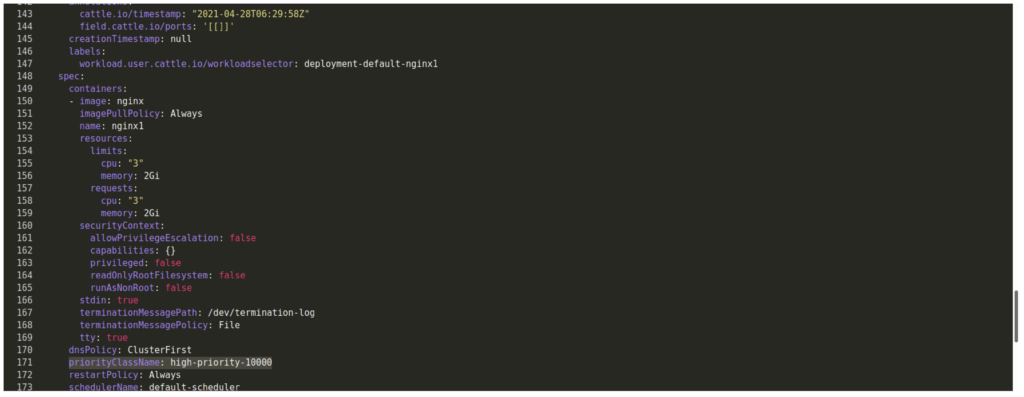

Finally, nginx1 squeezed out all nginx0