Ngrams 在部分匹配的应用
之前提到:“只能在倒排索引中找到存在的词。” 尽管 prefix 、 wildcard 、 regexp 查询告诉我们这种说法并不完全正确,但单个词的查找 确实 要比在词列表中盲目挨个查找的效率要高得多。在搜索之前准备好供部分匹配的数据可以提高搜索的性能。
在索引时准备数据意味着要选择合适的分析链,这里部分匹配使用的工具是 n-gram 。可以将 n-gram 看成一个在词语上 滑动窗口 , n 代表这个 “窗口” 的长度。如果我们要 n-gram quick 这个词 —— 它的结果取决于 n 的选择长度:
- 长度 1(unigram): [
q,u,i,c,k] - 长度 2(bigram): [
qu,ui,ic,ck] - 长度 3(trigram): [
qui,uic,ick] - 长度 4(four-gram): [
quic,uick] - 长度 5(five-gram): [
quick]
朴素的 n-gram 对 词语内部的匹配 非常有用,即在 Ngram 匹配复合词 介绍的那样。但对于输入即搜索(search-as-you-type)这种应用场景,我们会使用一种特殊的 n-gram 称为 边界 n-grams (edge n-grams)。所谓的边界 n-gram 是说它会固定词语开始的一边,以单词 quick 为例,它的边界 n-gram 的结果为:
qququiquicquick
可能会注意到这与用户在搜索时输入 “quick” 的字母次序是一致的,换句话说,这种方式正好满足即时搜索(instant search)!
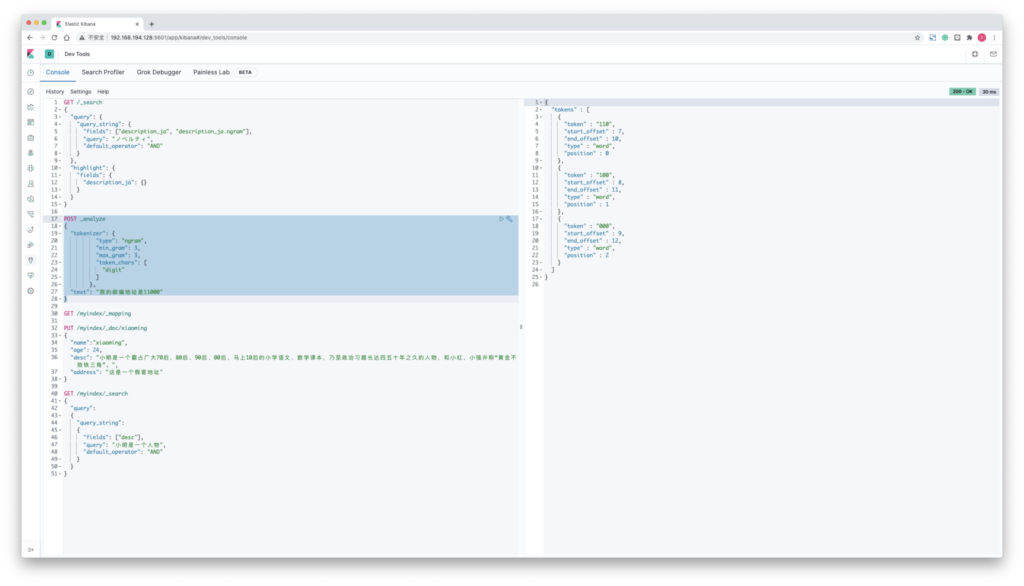
POST _analyze
{
"tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
},
"text": "我的邮编地址是11000"
}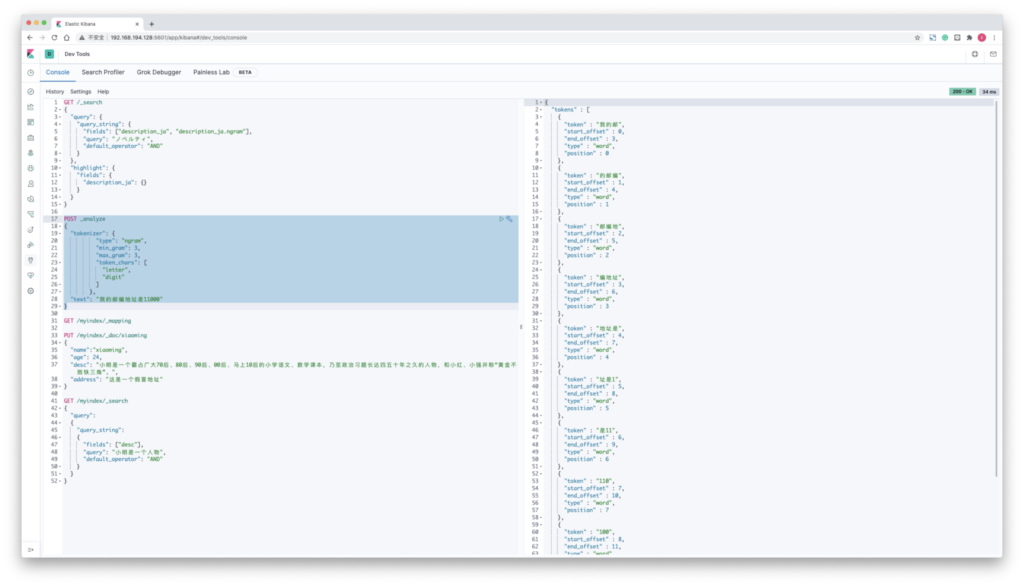
POST _analyze
{
"tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": [
"digit"
]
},
"text": "我的邮编地址是11000"
}