Term
匹配一个值,且输入的值不会被分词器分词
{
"query":{
"term":{
"foo": "hello world"
}
}
}文本“I say hello world”会被分词进行存储,不会存在“hello world”这整个词,那么不会返回任何值
但是如果使用“hello”作为查询条件,则只要数据中包含“hello”的数据都会被返回,分词对这个查询影响较大。
match_phase
match_phase习语匹配,查询确切的phase,在对查询字段定义了分词器的情况下,会使用分词器对输入进行分词,然后返回满足下述两个条件的document:
1.match_phase中的所有term都出现在待查询字段之中
2.待查询字段之中的所有term都必须和match_phase具有相同的顺序
{ "foo":"I just said hello world" }
{ "foo":"Hello world" }
{ "foo":"World Hello" }前两条会被命中
Match
模糊匹配,先对输入进行分词,对分词后的结果进行查询,文档只要包含match查询条件的一部分就会被返回
关于ElasticSearch的9200和9300端口区别
9200作为Http协议,主要用于外部通讯
9300作为Tcp协议,jar之间就是通过tcp协议通讯
ES集群之间是通过9300进行通讯
内存大小设置
Elasticsearch config 目录下的
jvm.options 文件
-Xms1g
-Xmx1g
默认的堆大小(最大和最小都是)为 2GB
分片和副本
默认配置为 5 个分片 1个副本
最理想的分片数量应该依赖于节点数量
因此,如果计划将来使用10个节点,那么就给索引配置10个分片。
为了保证 高可用 和 查询吞吐量,需要配置副本,如果副本量为 1
最终会生成 20 个分片,10个主分片,10个从分片(10个副本)
所需最大节点数 = 分片数 * (副本数+1)
20 = 10 * (1+1)
Elasticsearch一个分片实际上是一个 Lucene 索引
更多的分片意味着每个较小的 Lucene 索引上执行的操作会更快(尤其是索引过程)。
有时,这是一个很好的理由去使用更多的分片。
当然,将查询拆散成对每个分片的请求然后再合并结果,这也是有代价的。
这个对于 使用具体的参数来过滤 查询的应用程序是可以避免的。这时需要使用路由
拥有多个分片 和 拥有多个索引 有什么不同?
从技术上讲,他们的区别不大
默认情况下,Elasticsearch 只为每个索引分片创建一个副本
不同于分片的数量,副本的数量可以通过相关的API 随时更改。
使用副本可以应对不断增长的并发查询, 增加副本数量可以让查询负载分散到更多机器上
该功能能让构建
– index 体现了逻辑空间的概念,是一个逻辑意义上的聚合。
一个 Elasticsearch 集群可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性
– shard 分片体现了物理空间的观念,索引中的数据具体存放的地方。
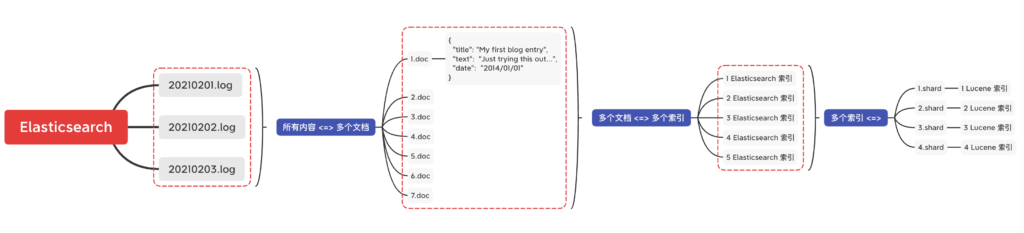
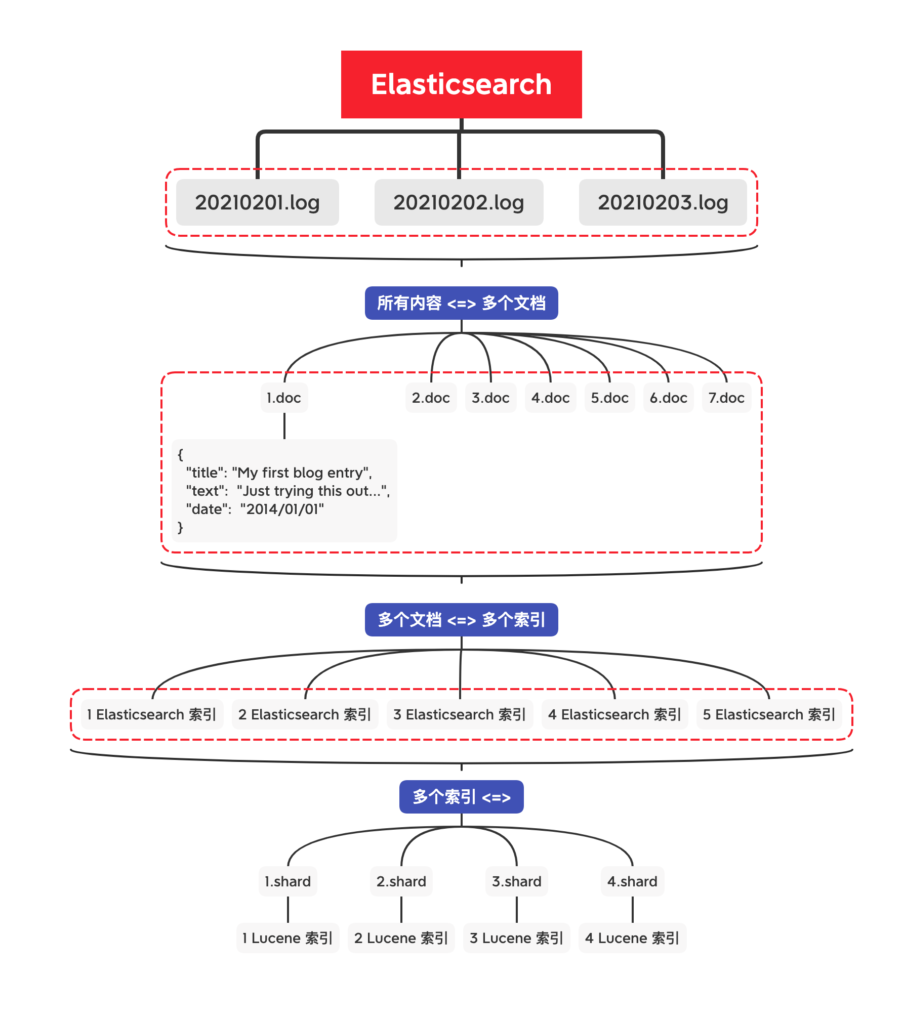
使用分片能够存储超过单节点容量限制的数据
使用副本则解决了 日渐增长的 吞吐量、高可用 和 容错 的问题
使用过多副本的缺点也很明显,占用存储空间 和 构建副本的开销,主从分片 以及 副本之间的数据同步也存在开销
match查询
{ "foo":"I just said hello world" }
{ "foo":"Hello world" }
{ "foo":"World Hello" }- match query知道分词器的存在,会对filed进行分词操作,然后再查询
- match_all:查询所有文档
返回所有
GET _search
{
"query":{"match_all":{"boost":"1.2"}}
}
还可以加boost
GET _search
{
"query":{"match_all":{"boost":"1.2"}}
}
- multi_match:可以指定多个字段
GET _search
{
"query": {
"multi_match": {
"query": "の",
"type": "best_fields",
"fields": [
"title",
"content"
],
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}
- match_phrase:短语匹配查询,ElasticSearch引擎首先分析(analyze)查询字符串,从分析后的文本中构建短语查询,这意味着必须匹配短语中的所有分词,并且保证各个分词的相对位置不变
{
"query": {
"match_phrase": {
"foo": "Hello World"
}
}
}会返回前两条
返回版本号,并且控制 size
GET _search
{
"version":true,
"from":0,
"size":1,
"query": {
"multi_match": {
"query": "の",
"type": "best_fields",
"fields": [
"org",
"voice_type"
],
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}
指定返回的字段
GET _search
{
"version":true,
"from":0,
"size":1,
"_source":["ask_type","post_date_time"],
"query": {
"multi_match": {
"query": "の",
"type": "best_fields",
"fields": [
"org",
"voice_type"
],
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
}
keyword
text类型
1:支持分词,全文检索,支持模糊、精确查询,不支持聚合,排序操作;
2:text类型的最大支持的字符长度无限制,适合大字段存储;
使用场景:
存储全文搜索数据, 例如: 邮箱内容、地址、代码块、博客文章内容等。
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
默认结合标准分析器进行词命中、词频相关度打分。
keyword
GET /_search
{
"query": {
"match": {
"org": "男性用"
}
},
"sort":[
{
"store_code.keyword":{
"order":"desc",
"unmapped_type" : "long"
}
}
]
}1:不进行分词,直接索引,支持模糊、支持精确匹配,支持聚合、排序操作。
2:keyword类型的最大支持的长度为——32766个UTF-8类型的字符,可以通过设置ignore_above指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
使用场景:
存储邮箱号码、url、name、title,手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。
用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。
直接将完整的文本保存到倒排索引中。
Dynamic
dynamic属性:默认值为true,允许动态地向文档类型中加入新的字段。推荐设置为false,禁止向文档中添加字段,这样,文档类型的所有字段必须在索引映射的properties属性中显式定义,在properties字段中未定义的字段都将会ElasticSearch忽略。
dynamic设置为ture:默认值,新增加的字段被添加到索引映射中;
dynamic设置为false:新增加的字段会被忽略;
dynamic设置为strict:当向文档中新增字段时,ElasticSearch引擎抛出异常;wildcard
GET /_search
{
"query": {
"wildcard": {
"store_name": "*店"
}
}
}
允许使用通配符* 和 ?来进行查询
*代表0个或多个字符
?代表任意一个字符
term查询和terms查询
term query会去倒排索引中寻找确切的term,它并不知道分词器的存在。这种查询适合keyword 、numeric、date。
term:查询某个字段里含有某个关键词的文档
terms:查询某个字段里含有多个关键词的文档
a、term 和 terms 是 包含(contains) 操作,而非 等值(equals) (判断)
b、不知道分词器的存在,所以不会去分词,
c、所谓的包含是文档分词结果某个分词是否相等,即文档是否包含这个分词
d、因为是在分词结果中匹配,所以大写要转换为小写,大写字母是匹配不到
GET /_search
{
"query":{"term":{ "country_code.keyword":"JP"}}
}
GET /_search
{
"query":{"terms":{ "country_code.keyword":["JP","US"]}}
}
fuzzy
fuzzy 查询是 term 查询的模糊等价。
a、是 包含(contains) 操作,而非 等值(equals) (判断)。
b、不知道分词器的存在,所以不会去分词,
c、所谓的包含是文档分词结果某个分词是否包含,不是整个文档是否包含
d、因为是在分词结果中匹配,所以大写要转换为小写,大写字母是匹配不到
value:查询的关键字
boost:查询的权值,默认值是1.0
min_similarity:设置匹配的最小相似度,默认值为0.5,对于字符串,取值为0-1(包括0和1);对于数值,取值可能大于1;对于日期型取值为1d,1m等,1d就代表1天
prefix_length:指明区分词项的共同前缀长度,默认是0
max_expansions:查询中的词项可以扩展的数目,默认可以无限大
hightlights
GET /_search
{
"query":{"fuzzy":{ "store_name":"店"}}
, "highlight": {"fields": {"store_code": {}}}
}



