ELasticsearch 会读取映射字段的所有默认属性,并开始按照如下方式处理它们
如果该字段已经存在于映射中并且该字段值有效(它与正确对的类型匹配),那么ELasticsearch 不需要更改当前映射
如果该字段已经存在于映射中,但该字段的值具有不同的类型,则ELasticsearch将尝试升级该字段的类型(例如,从integer整型更改为long长整型)。如果类型不兼容则抛出异常,索引过程将失败
如果该字段不存在,那么ELasticsearch将尝试自动检测字段的类型。它将使用新的字段映射更新映射
为了或得更好的索引结果和性能,需要手动定义映射
减少磁盘上的索引大小(禁用自定义字段的功能)
仅对感兴趣的字段建立索引(这样做通常会加快速度)
预处理数据以进行快速搜索和实时分析
正确定义必须一多个标记分析字段还是将其视为单个标记
创建索引
PUT /myindex
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
}
DELETE myindex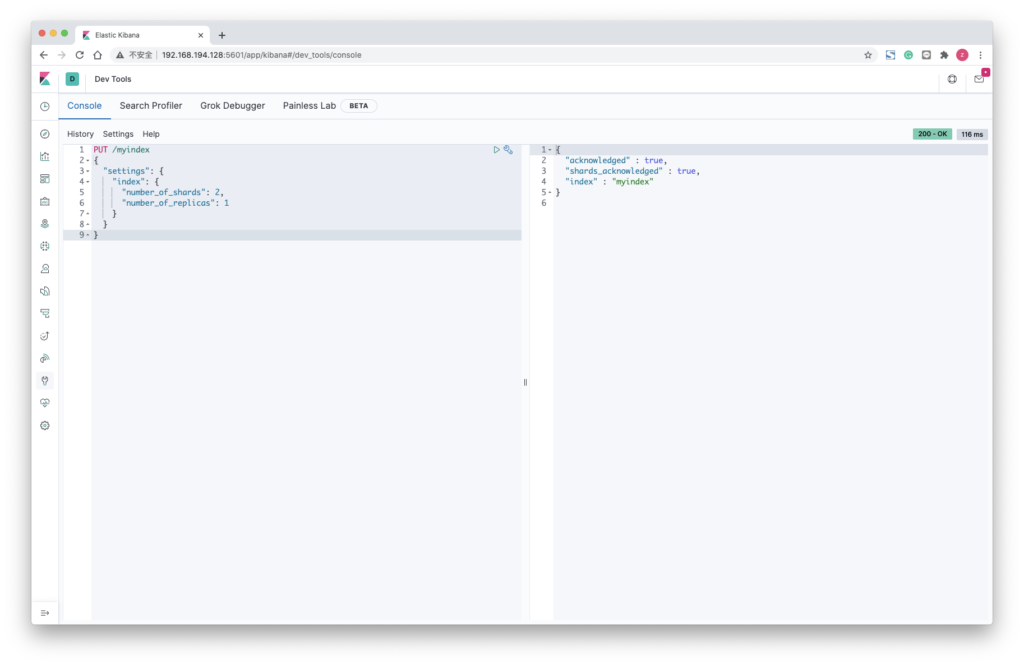
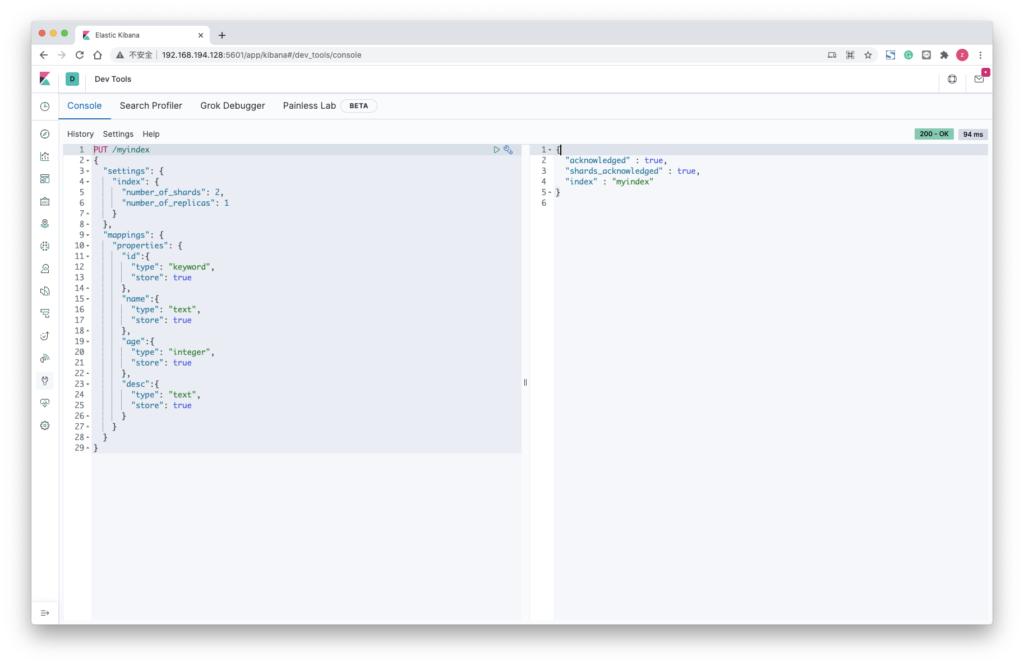
携带mapping信息
PUT /myindex
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword",
"store": true
},
"name":{
"type": "text",
"store": true
},
"age":{
"type": "integer",
"store": true
},
"desc":{
"type": "text",
"store": true
}
}
}
}
打开或关闭索引
如果想要保留数据并且节省资源 (内存或CPU)
则删除索引的一种不错的代替方法是,关闭它们
ELasticsearch 允许你打开或者关闭索引,使其进入在线或离线模式
POST /myindex/_close
POST /myindex/_open索引关闭后,集群上没有开销(元数据状态除外):
索引分片已关闭,并且它们不适用文件描述符、内存和线程
关闭索引有很多用例
它可以禁用基于日期的索引(按日期存储其记录的索引)
当你在集群中的所有活动索引上进行搜索并且不想在某些索引中进行搜索时(在这种情况下,使用别名是最佳解决方案,但是也可以使用具有已关闭索引的别名来实现相同的概念)
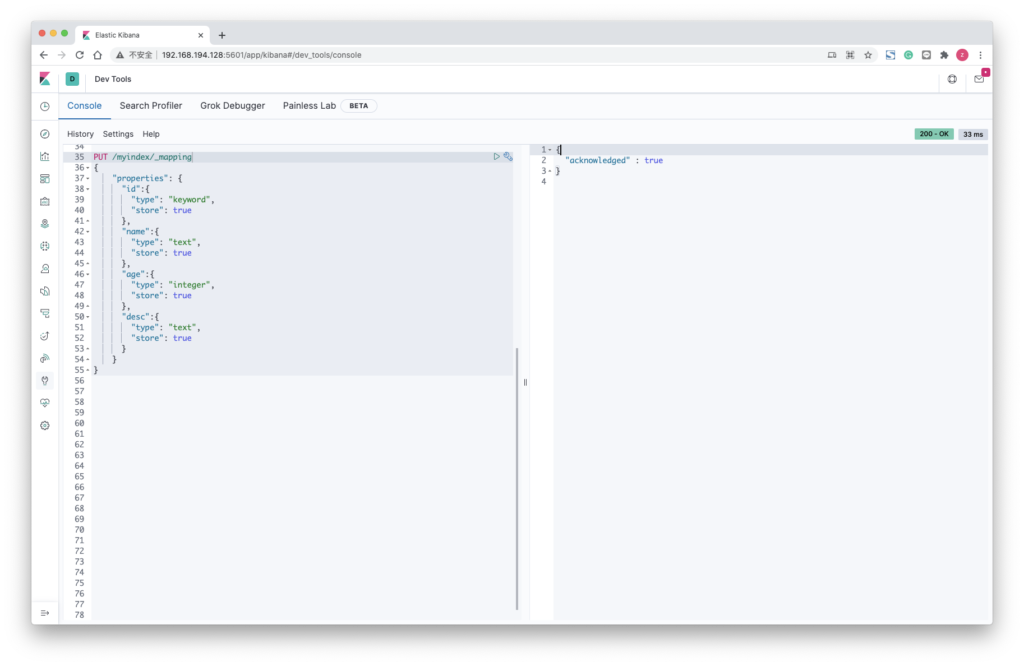
创建映射
PUT /myindex/_mapping
{
"properties": {
"id":{
"type": "keyword",
"store": true
},
"name":{
"type": "text",
"store": true
},
"age":{
"type": "integer",
"store": true
},
"desc":{
"type": "text",
"store": true
}
}
}
GET /myindex/_mapping?pretty没有删除索引的操作,要删除或者更改映射,需要执行以下步骤
- 使用新的或修改的映射创建新索引
- 重新索引所有记录
- 删除具有错误映射的旧索引
重建索引
有很多常见的情况都涉及更改映射。
由于无法删除已经定义的映射,因此需要为索引数据重建索引
- 更改映射分析器
- 在映射中添加新字段,随后你需要重新处理所有记录以搜索新的子字段
- 删除未使用的映射
- 更改需要新映射的记录结构
POST /_reindex?pretty=true
{
"source": {
"index": "myindex"
},
"dest": {
"index": "myindex2"
}
}- 创建 myindex ,设置 mapping ,传入数据
- 创建 myindex2 , 设置 mapping
- 调用上面脚本
- myindex2 或得数据
刷新索引
ELasticsearch 允许用户对索引的强制刷新来控制搜索器的状态。
如果未强制刷新,则新索引的文档只能在固定的时间间隔 默认1秒 后才能被搜索
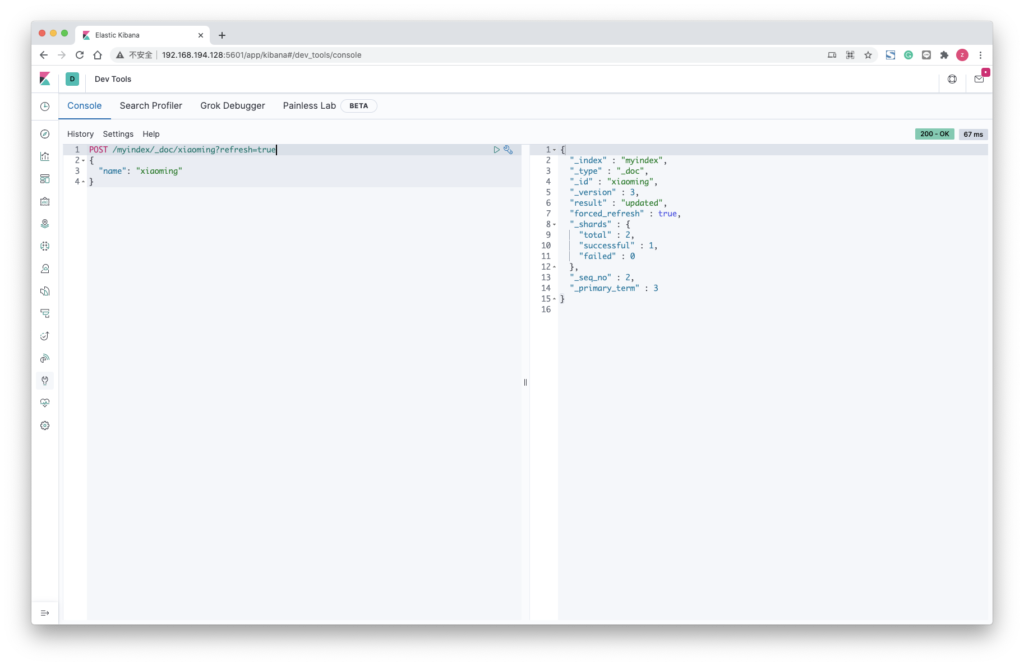
POST /myindex/_refresh调用刷新的最佳时间是对大量数据建立索引之后,以确保可以立即搜搜记录,通过将 refresh = true 添加为查询参数,可以在文档创建索引期间强制刷新
POST /myindex/_doc/xiaoming?refresh=true
{
"name": "xiaoming"
}
冲洗索引
出于性能原因,ELasticsearch 将一些数据存储在内存中和事务日志上,如果需要释放内存,则需要清空事务日志,并确保将数据安全地写入磁盘,因此需要冲洗 Flush 索引
POST /myindex/_flush
POST /_flush强制合并索引
ELasticsearch 核心是基于 Lucene 的, 而Lucene则会将数据分段存储在磁盘上。
在索引有效期内,会创建和更改许多段。随着段号的增加,由于读取所有段所需的时间,搜索速度会降低。强制合并 ForceMerge 操作使我们可以合并索引,以提高搜索性能并减少分段。
POST /myindex/_forcemerge
POST /_forcemergeLucene 中的forcemerge 操作试图通过 删除未使用的段,清除已删除的文档并以最小的段数重建索引,从而以大量 I/O 的方式减少分段
主要优点在于
- 减少了文件描述符
- 释放段读取器使用的内存
- 减少了段的管理,提高了搜索过程中的性能
过程中索引可能会没有响应
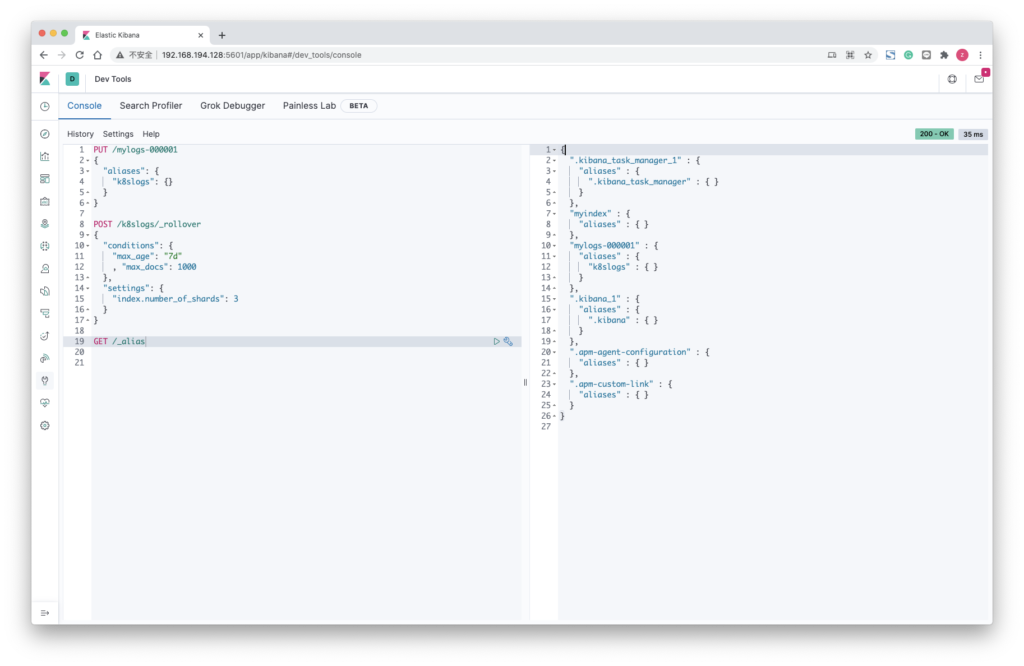
使用索引别名
需要跨越索引进行查询时,可以使用别名,将它们分组
GET /_aliases
GET /_alias
PUT /myindex/_alias/myali
PUT /.kibana_1/_alias/myali
GET /myali
DELETE /myindex/_alias/myali
DELETE /*/_alias/myali滚动索引
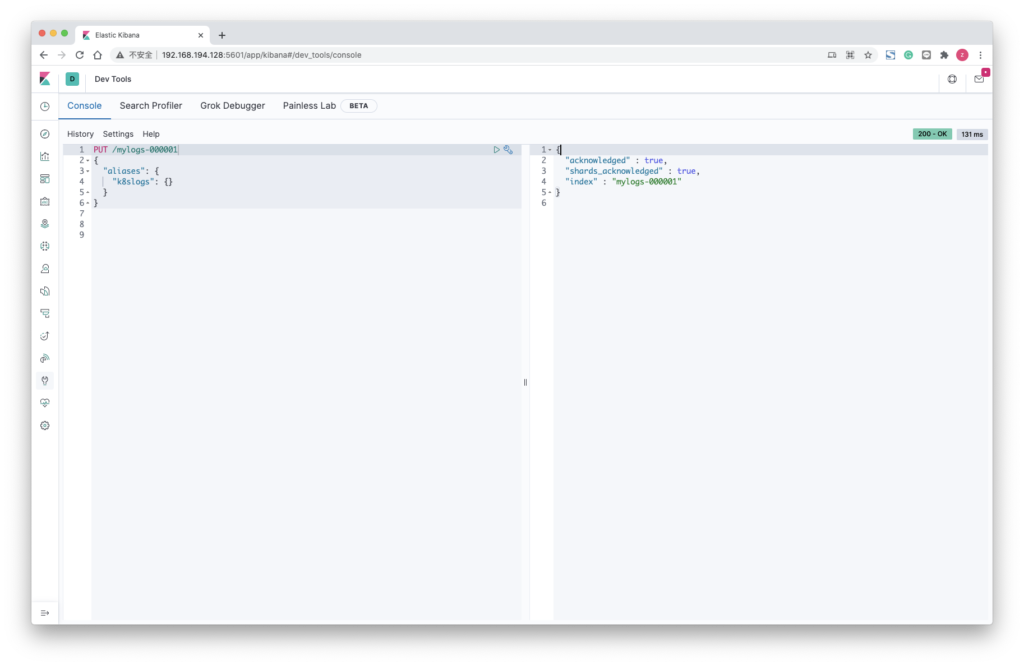
滚动索引是一个特殊的别名,当条件之一被匹配时,该别名将管理新索引的自动创建
命名约定由 ELasticsearch 管理, ELasticsearch 会自动增加索引名称的数字部分,默认情况下,它使用 6个结尾数字
PUT /mylogs-000001
{
"aliases": {
"k8slogs": {}
}
}
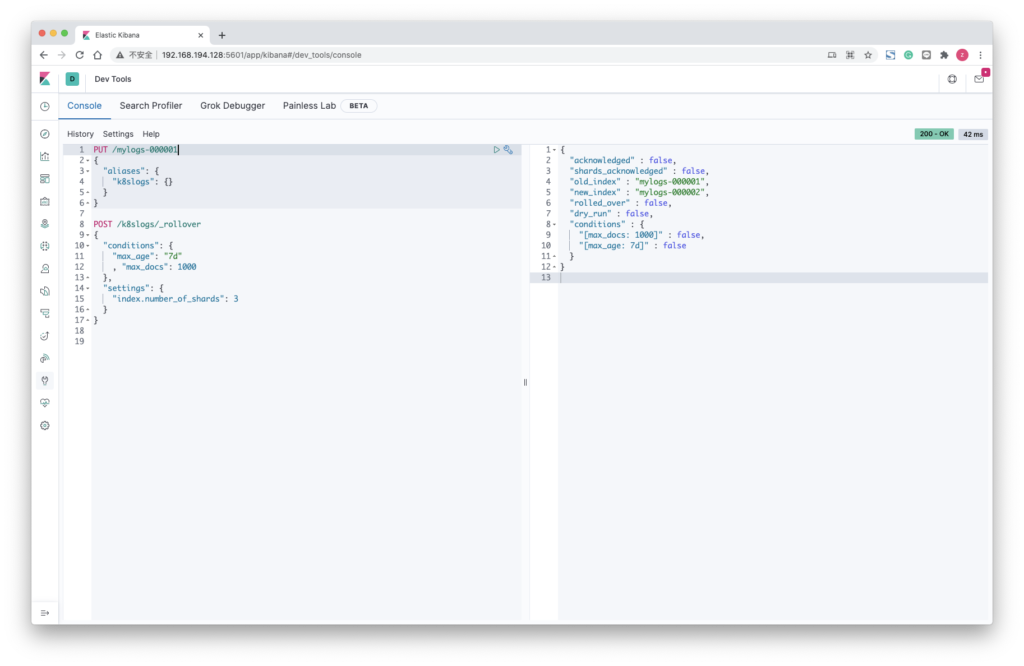
POST /k8slogs/_rollover
{
"conditions": {
"max_age": "7d"
, "max_docs": 1000
},
"settings": {
"index.number_of_shards": 3
}
}
缩小索引
ELasticsearch 提供了优化索引的新方法
使用 缩小 Shrink API,可以减少索引的分片数量。
此功能针对以下几种常见方案
- 在初始设计大小期间,分片数量往往会指定的不合适。
- 减少分片数量以减少内存和资源使用
- 减少分片数量以加快搜索速度
缩小API 是通过执行以下步骤来减少分片的数量
ELasticsearch 创建一个新的索引目标,其定义与原索引相同,但主分片数量更少
ELasticsearch 将分片段从原索引硬链接(或复制)到目标索引
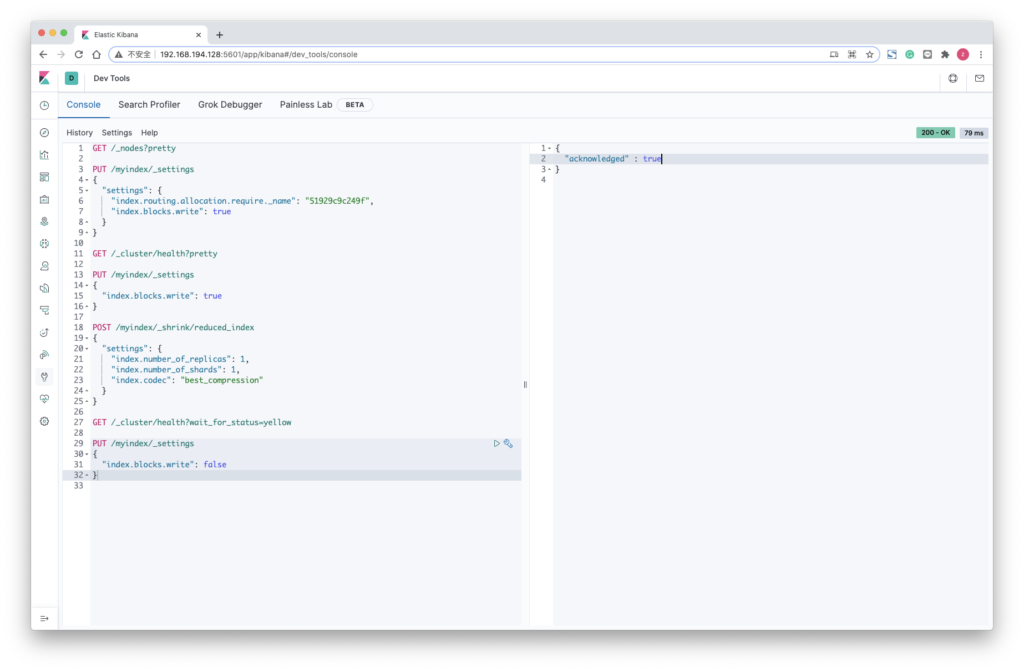
要缩小索引,可执行以下步骤
- 所有被缩小的索引的主分片都需要在同一节点上。
所以这里需要节点名称
GET /_nodes?pretty“name” : “51929c9c249f”,
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "docker-cluster",
"nodes" : {
"qFMuUvbPTJeB8uism4TD6Q" : {
"name" : "51929c9c249f",
"transport_address" : "172.17.0.2:9300",
"host" : "172.17.0.2",
"ip" : "172.17.0.2",
"version" : "7.7.1",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "ad56dce891c901a492bb1ee393f12dfff473a423",
"total_indexing_buffer" : 107374182,
"roles" : [2. 强制固定索引到这个要使用的节点
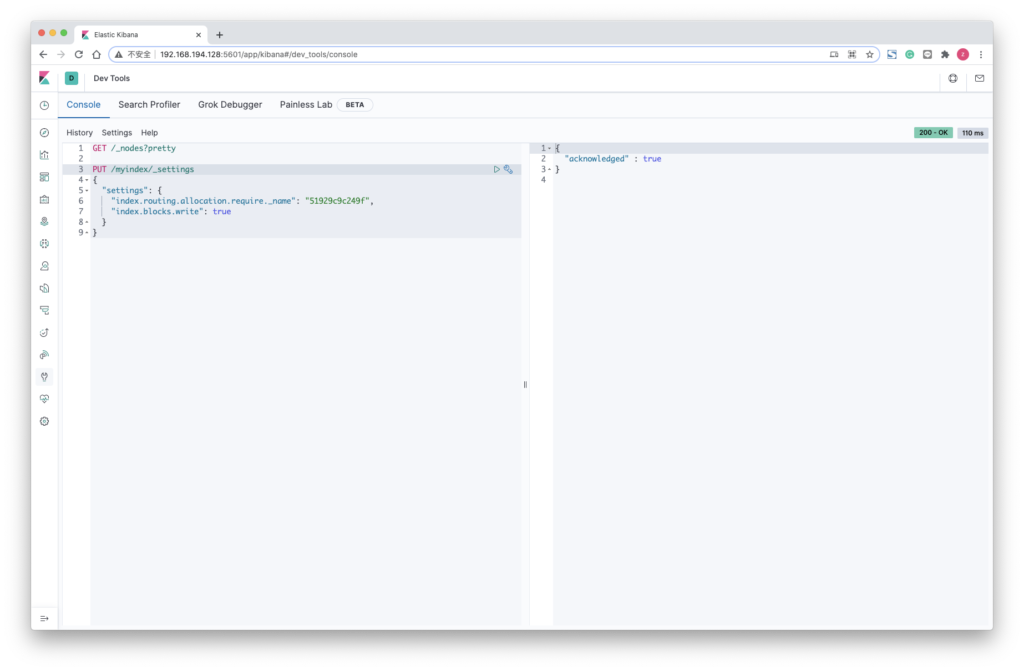
PUT /myindex/_settings
{
"settings": {
"index.routing.allocation.require._name": "51929c9c249f",
"index.blocks.write": true
}
}
3. 检查是否所有分片都已重定位,通过检查green状态 ( yellow 就说明可以了)
GET /_cluster/health?pretty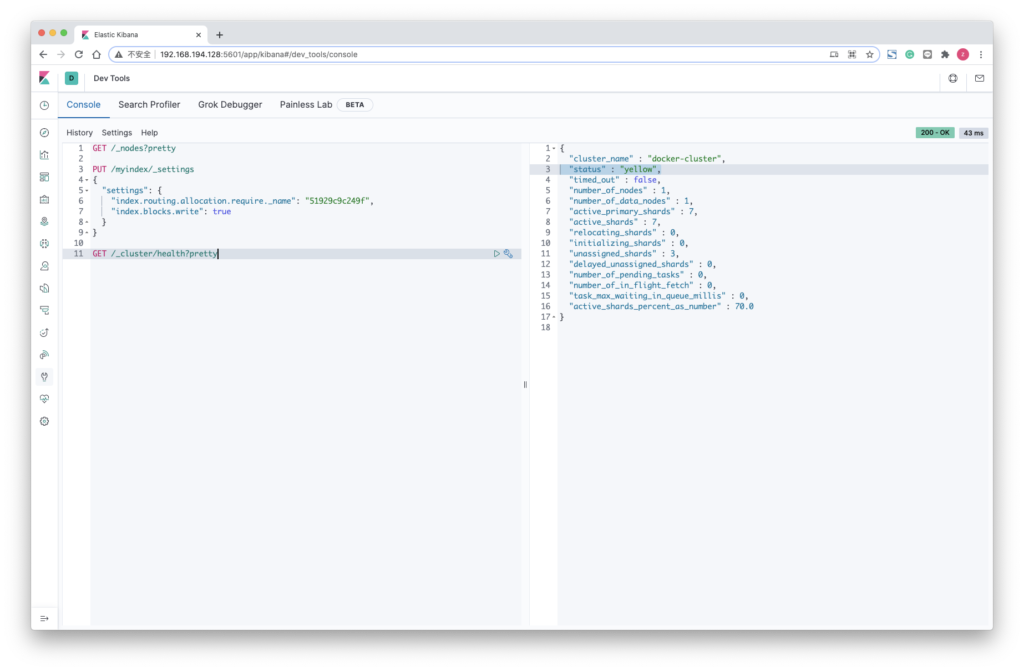
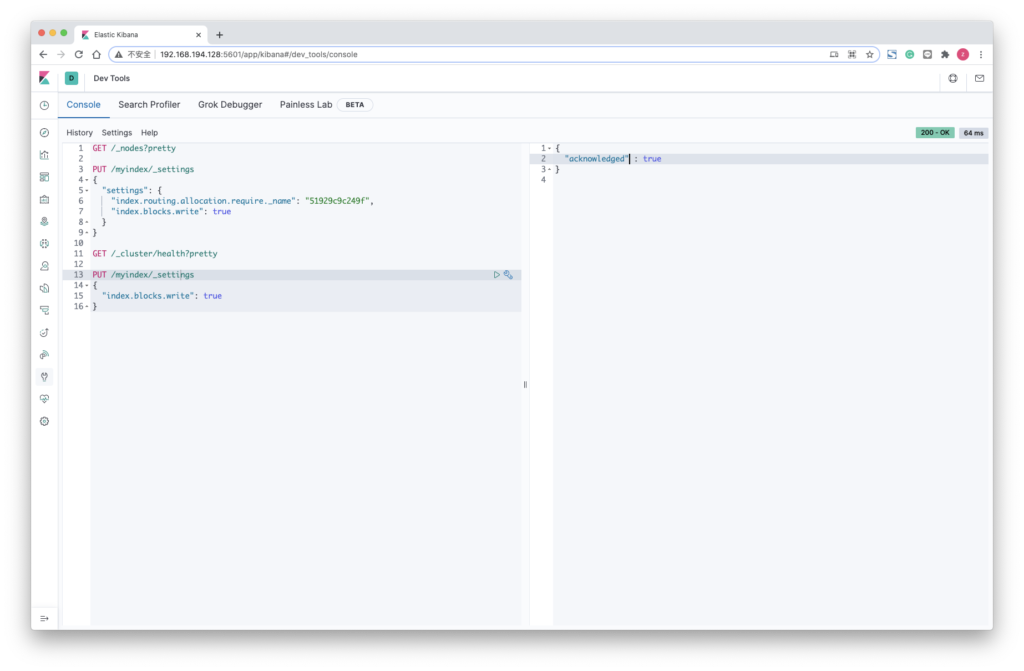
4. 索引应处于只读状态才能进行缩小操作
PUT /myindex/_settings
{
"index.blocks.write": true
}
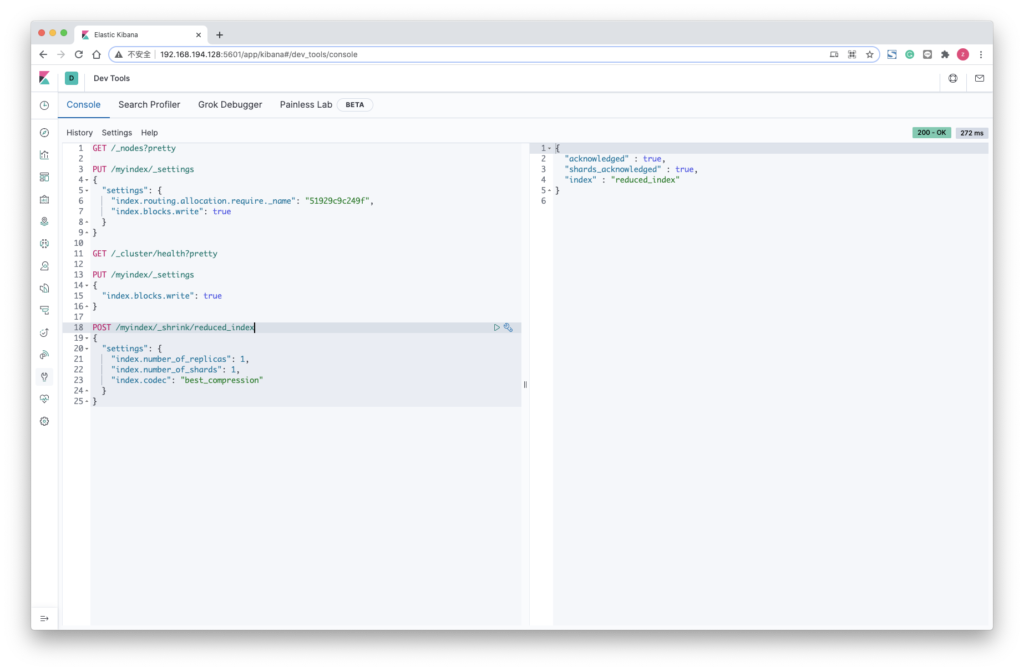
5. 创建缩小的索引
POST /myindex/_shrink/reduced_index
{
"settings": {
"index.number_of_replicas": 1,
"index.number_of_shards": 1,
"index.codec": "best_compression"
}
}
6. 检查状态,等待 yellow
GET /_cluster/health?wait_for_status=yellow
7. 删除刚刚的只读配置
PUT /myindex/_settings
{
"index.blocks.write": false
}