处理同义词
同义词用于拓宽匹配文档的范围
要在搜索中使用同义词,相应的字段就要提前配置同义词词条过滤器。
这个过滤器允许在 setting 中直接设置同义词,也可以从文件中获得同义词
简单收缩 单词扩展
u s a , united states => usa
gb => britain,england简单扩展
在索引时使用简单扩展主要有两个缺点
一是会让索引变得异常大
二是对于现有文档,要改变同义词规则就必须重新索引它们
不过索引速度会非常快,因为 Elasticsearch 只需要查找一个词项
但是如果在查询时使用,就可能会对搜索速度造成极大的性能影响,因为对单一词项的查询也会被改写成寻找它的同义词组中的所有词项。
在查询时使用简单查询最大的优点是,不需要重新索引文档就可以更新同义词规则
简单收缩
简单收缩会将左侧的一组同义词映射成右边的一个词,这种方法有许多优点
首先,索引大小很正常,因为一个词项替换了整个同义词组
其次,查询性能非常好,因为只需要匹配一个词项
第三,同义词规则更新时不需要重新索引文档
无论什么时候,当更新了任意的同义词规则时,都需要关闭索引再重新打开,通过这种方法来把新规则导入索引设置
简单收缩也有缺点,它会极大的影响相关性。
属于同一个同义词组的所有词项,都有相同的反向文档频率,因此将无法区分最常见和最不常见的单词
gb => gb,greatbritain
britain => britain,gb,greatbritain- 对 britain 查询,只能找到关于britain 的文档
- 对 gb 查询,会找到 gb 和 britain 的文档
- 对 greatbritain 查询会找到关于 gb、britain 或者 greatbritain 的文档
处理多词同义词会有如下问题
online sale , online revenues => revenue如果一份文档中只包含了 online 这个词,就不会被匹配
要避免这种情况出现,就要分别为每个可能的词项单独创建同义词规则
举例
/usr/share/elasticsearch/config/analysis/synonyms.txt
j2ee,javac,jvm,jsp => java
java => j2ee,javac,jvm
java,scala,kotlin,groovy => groovy,jruby
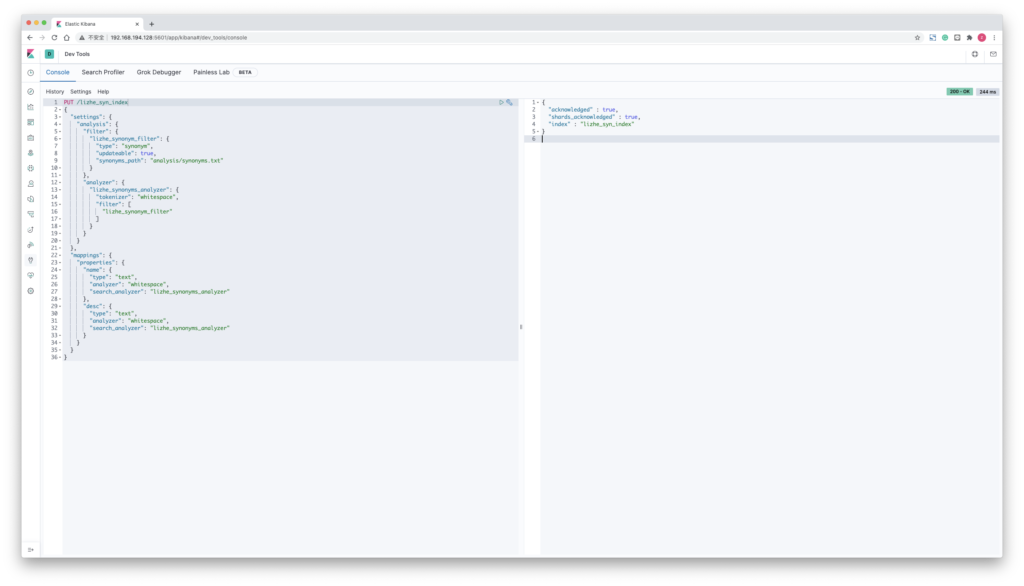
PUT /lizhe_syn_index
{
"settings": {
"analysis": {
"filter": {
"lizhe_synonym_filter": {
"type": "synonym",
"updateable": true,
"synonyms_path": "analysis/synonyms.txt"
}
},
"analyzer": {
"lizhe_synonyms_analyzer": {
"tokenizer": "whitespace",
"filter": [
"lizhe_synonym_filter"
]
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "lizhe_synonyms_analyzer"
},
"desc": {
"type": "text",
"analyzer": "whitespace",
"search_analyzer": "lizhe_synonyms_analyzer"
}
}
}
}
插入一些测试用的数据
PUT /lizhe_syn_index/_doc/java
{
"name": "java",
"desc": "i am java"
}上面的结构,如果查询java
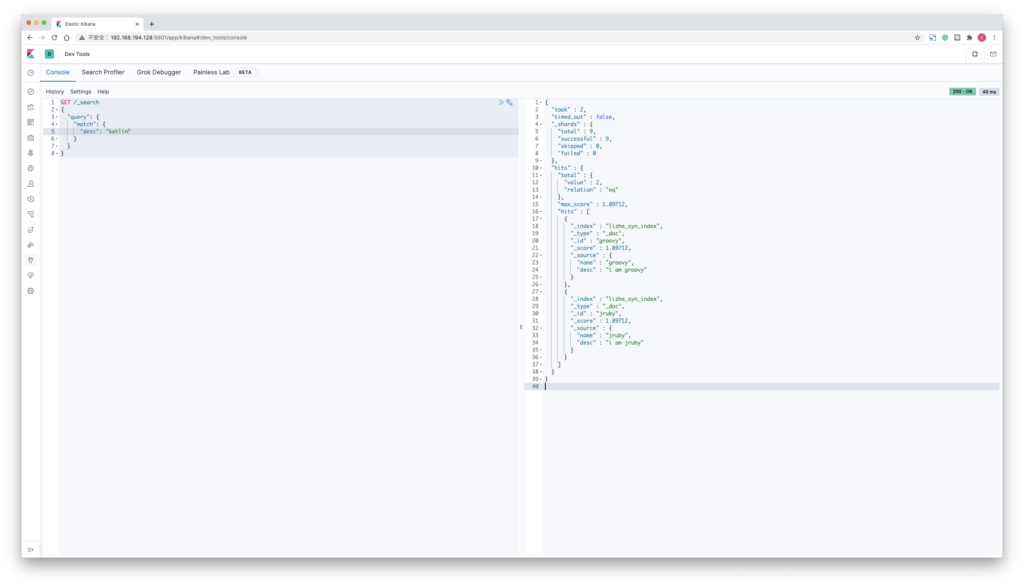
GET /_search
{
"query": {
"match": {
"desc": "java"
}
}
}会命中
j2ee、javac、jvm、groovy、jruby也就是这一部分
java => j2ee,javac,jvm
java,scala,kotlin,groovy => groovy,jruby如果查询 j2ee 或者是 javac ,会命中
java参考
j2ee,javac,jvm,jsp => java如果查询 kotlin,会命中
groovy,jruby