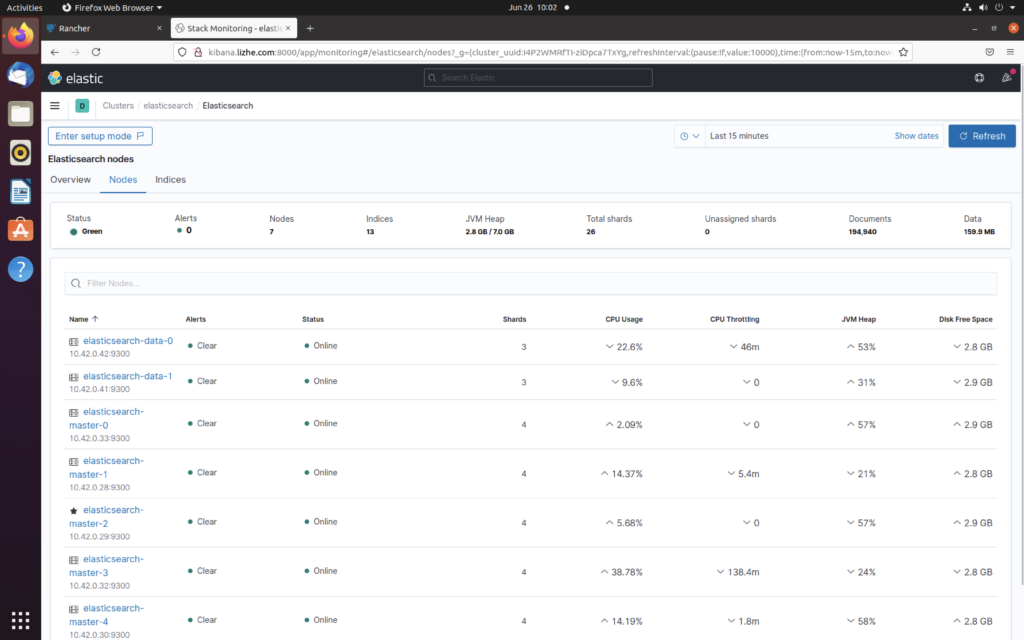
Elasticsearch、filebeat 和 kibana 是最常见的用来管理 kubernetes 集群日志的方式。
- 最简单的是使用 filebeat -> elsticsearch -> kibana
请参考 EFK安装
这种情况下最致命的缺点来自于 Elasticsearch 的吞吐量,提升Elasticsearch吞吐量的办法有很多,磁盘性能,节点的shard数量,master节点的性能,把Elasticsearch单机替换成集群模式,修改index.refresh_interval降低搜索的实时性换取更高的写入性能等等
2. 通过MQ来提升吞吐量 filebeat -> kafka -> logstash -> elasticsearch – > kibana
3. 为日志系统增加安全性验证
在 EFK安装 中提到了如何对单机版本的 Elasticsearch 和 kibana 使用 xpack 添加权限
问题在于 如果在 Elasticsearch 集群中 添加 xpack 权限的话,需要对 Elasticsearch 集群添加 https 证书验证
在kubernetes中进行此步骤会比较复杂,当然此种方法安全性是最高的,节点之间的通讯也通过了https加密,不过鉴于kubernetes集群内网中的Elasticsearch往往都是通过内网来通讯的,所以这点在很多情况下可以被忽略。
4 更简单的方式
本文主要为了提供一种既可以满足 大吞吐量 又 提供适度的安全性 的方案
filebeat -> kafka -> logstash -> elasticsearch cluster -> kibana -> traefik basic auth
以下是具体步骤
- Elasticsearch集群的安装
可以直接通过helm https://helm.elastic.co/
下面的values会创建5个master节点,当然如果需要 data、client 等节点可以通过values设定
---
antiAffinity: "soft"
replicas: "5"
resources:
requests:
cpu: "200m"
volumeClaimTemplate:
resources:
requests:
storage: "3Gi"
2. 安装kafka
3. 安装 filebeat 将抓取到的日志推送到 kafka
/usr/share/filebeat/filebeat.yml
filebeat.inputs:
- type: log
paths:
- /run/containerd/io.containerd.runtime.v1.linux/**/*.log
- /run/containerd/io.containerd.runtime.v1.linux/k8s.io/*/rootfs/usr/local/tomcat/app.log
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
output.kafka:
hosts: ["kafkasvc.efk.svc:9093"]
topic: 'estopic'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 10000004. 安装 Logstash , Logstash 从 kafka 读取数据,然后推送给 Elasticsearch
/usr/share/logstash/pipeline/logstash.conf
input {
kafka {
bootstrap_servers => ["kafkasvc.efk.svc:9092"]
group_id => "es-group"
topics => ["estopic"]
codec => json
}
}
filter {
}
output {
elasticsearch {
hosts => "http://elasticsearch-master.efk.svc:9200"
index => "kafka‐%{+YYYY.MM.dd}"
}
}/usr/share/logstash/config/logstash.yml
http.host: "0.0.0.0"5. 安装 kibana
kibana 环境变量
SERVER_HOST 0.0.0.0
NODE_OPTIONS --max-old-space-size=1800
ELASTICSEARCH_HOSTS http://elasticsearch-master:92006. 安装并且配置 traefik
https://helm.traefik.io/traefik
创建中间件 关于密码的生成请参考 Traefik basic auth
# Declaring the user list
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: dev-auth
namespace: efk
spec:
basicAuth:
secret: authsecret
---
# Note: in a kubernetes secret the string (e.g. generated by htpasswd) must be base64-encoded first.
# To create an encoded user:password pair, the following command can be used:
# htpasswd -nb user password | openssl base64
apiVersion: v1
kind: Secret
metadata:
name: authsecret
namespace: efk
data:
users: |2
dXNlcjE6JGFwcjEkeUw0OEFEWm8kazFmWW1RVTUuZjhwby9SSld6UFdMLwp1c2Vy
MjokYXByMSRJWXBvc1lSMCRuZWJGZ201ejEzdEh0VFVGUktZeVAxCnVzZXIzOiRh
cHIxJFZLTDVuckIzJG9iVUduR0FXSTYxMFNPUHZZblM2Vy4K创建ingressroute
kind: IngressRoute
metadata:
name: kibanaingress
namespace: efk
spec:
entryPoints:
- web
routes:
- match: Host(`kibana.lizhe.com`)
kind: Rule
services:
- name: kibanasvc
port: 5601
middlewares:
- name: dev-auth通过 ingress 访问 就会得到下面的 basic auth 验证

如何为Elasticsearch添加 data节点
使用同样的 helm
添加以下values
roles:
master: "false"
ingest: "false"
data: "true"
remote_cluster_client: "true"
ml: "true"
replicas: 2
resources:
requests:
cpu: "200m"
memory: "1Gi"
limits:
cpu: "1000m"
memory: "2Gi"
antiAffinity: "soft"
nodeGroup: "data"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 3Gi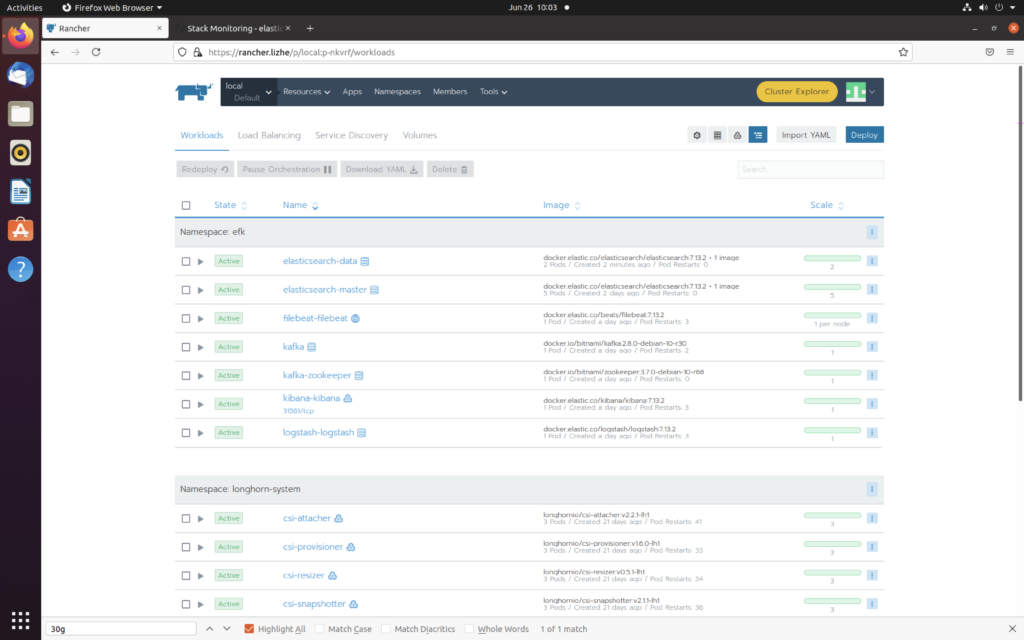
可以看到 Elasticsearch 节点 从5个master 变成了7个,多出了2个data节点