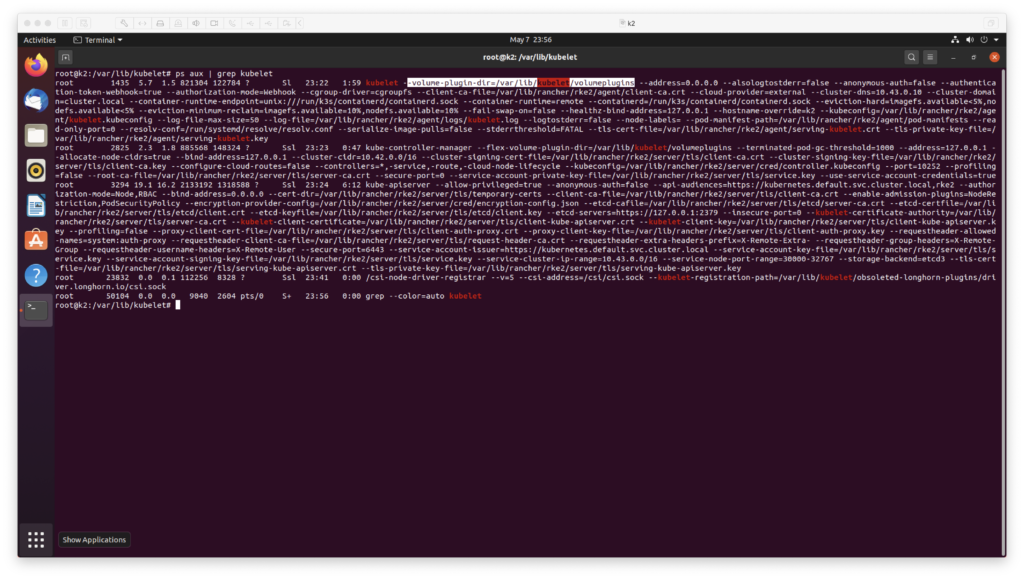
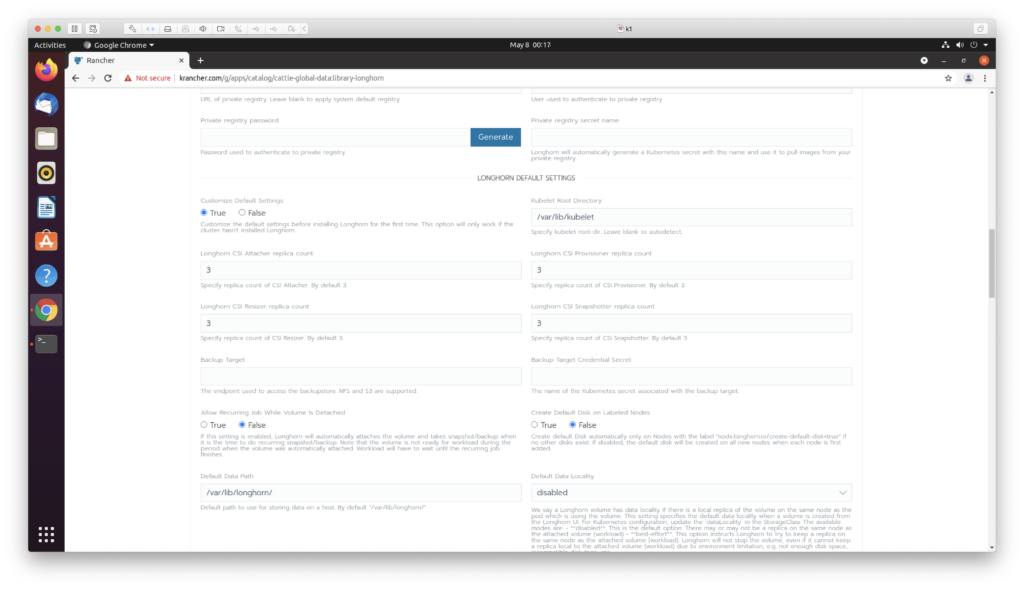
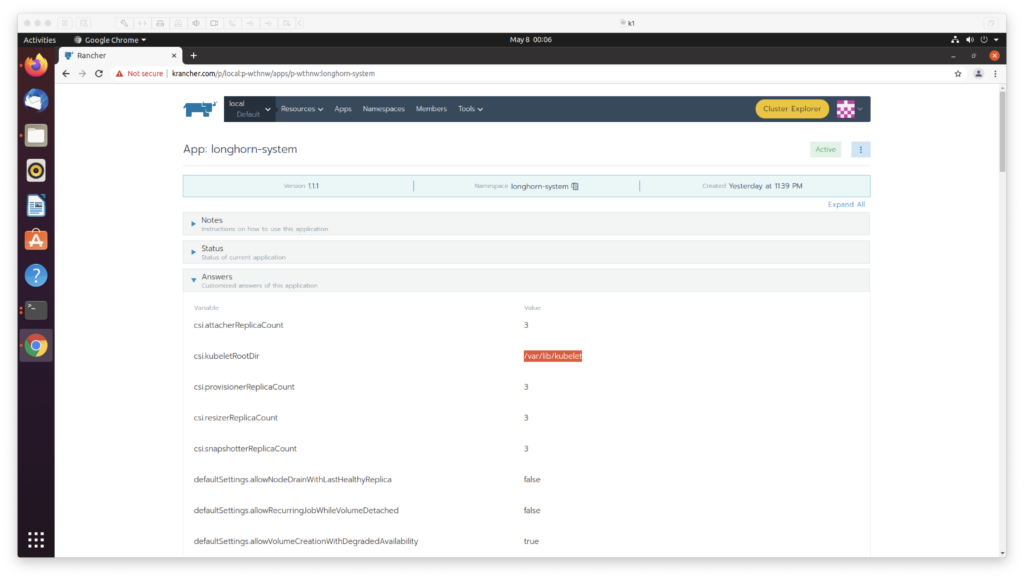
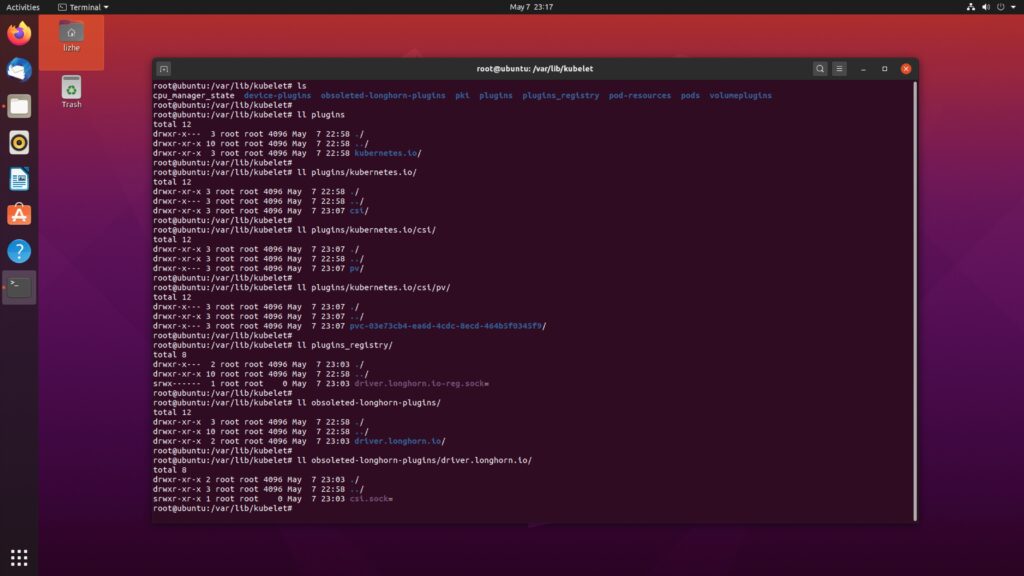
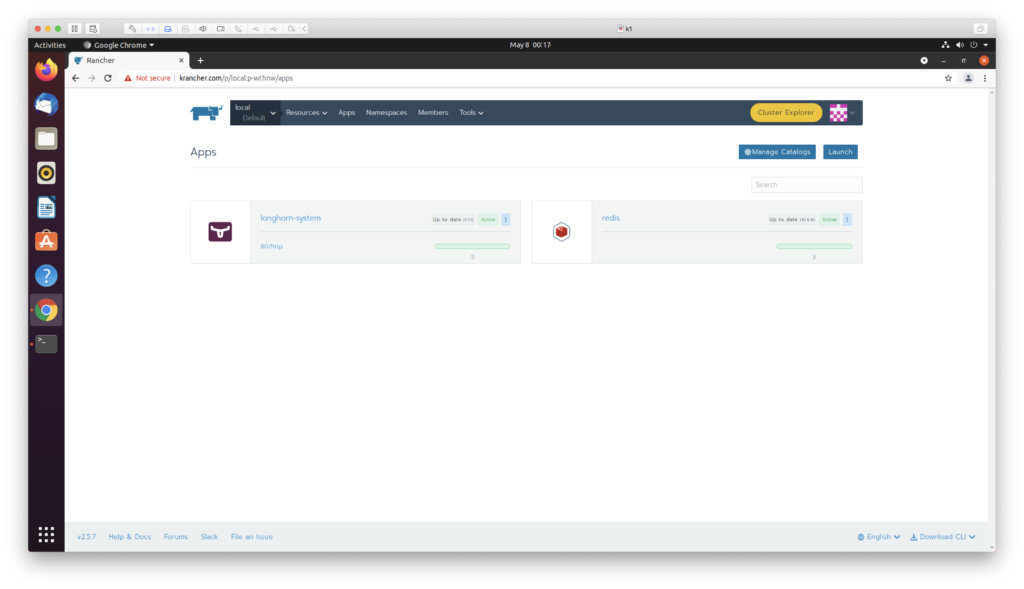
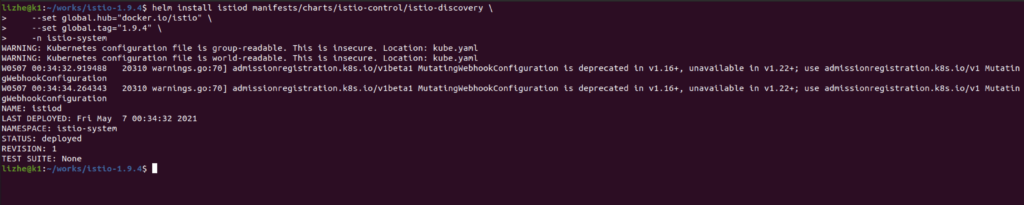
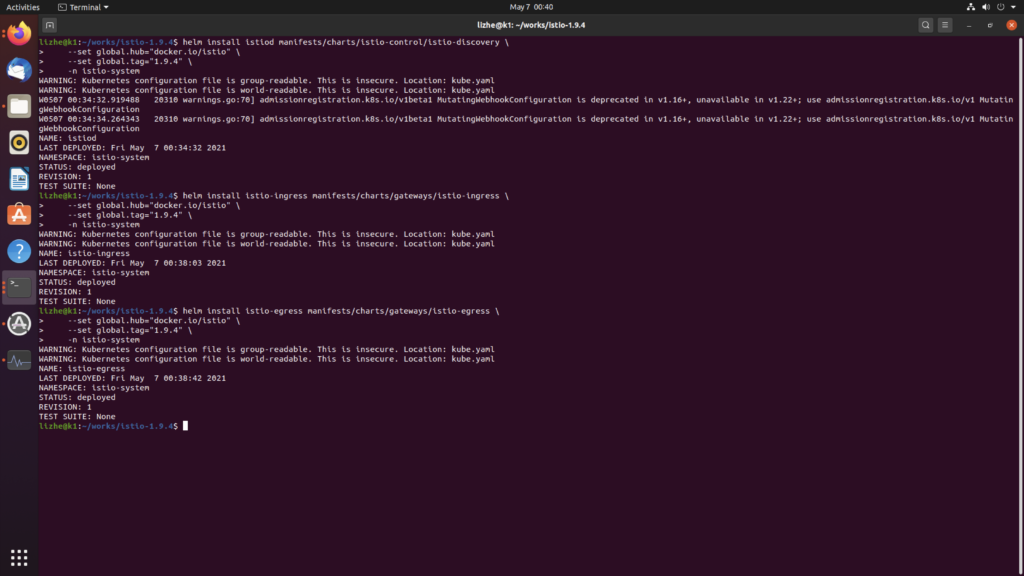
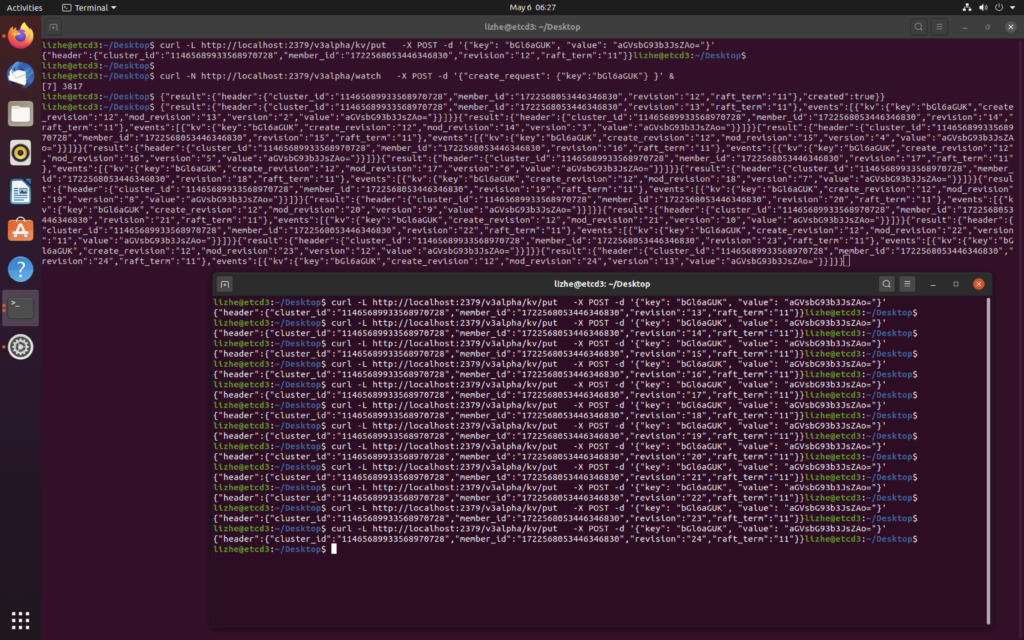
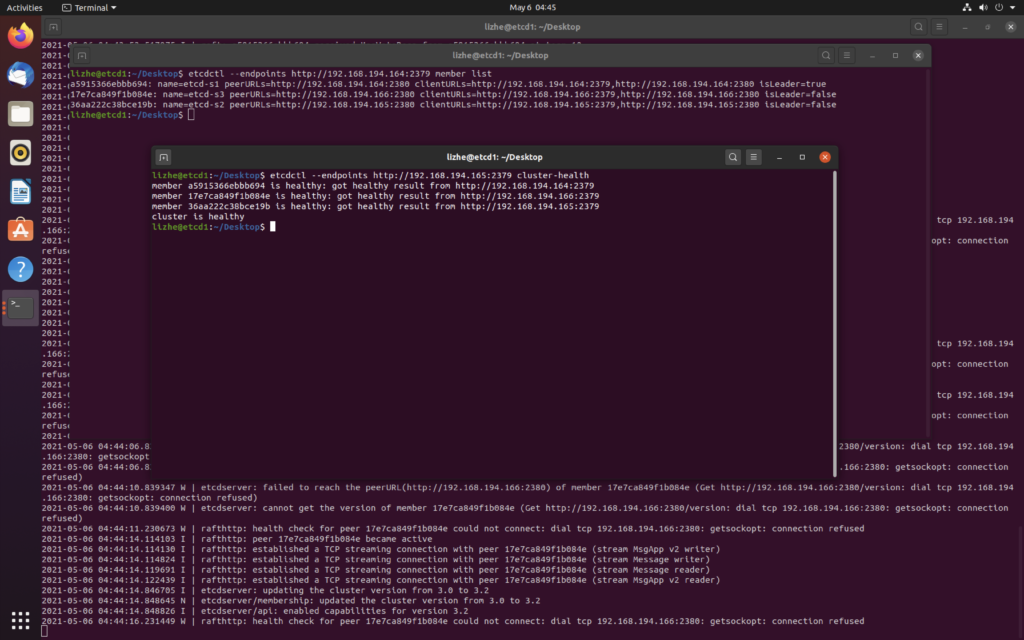
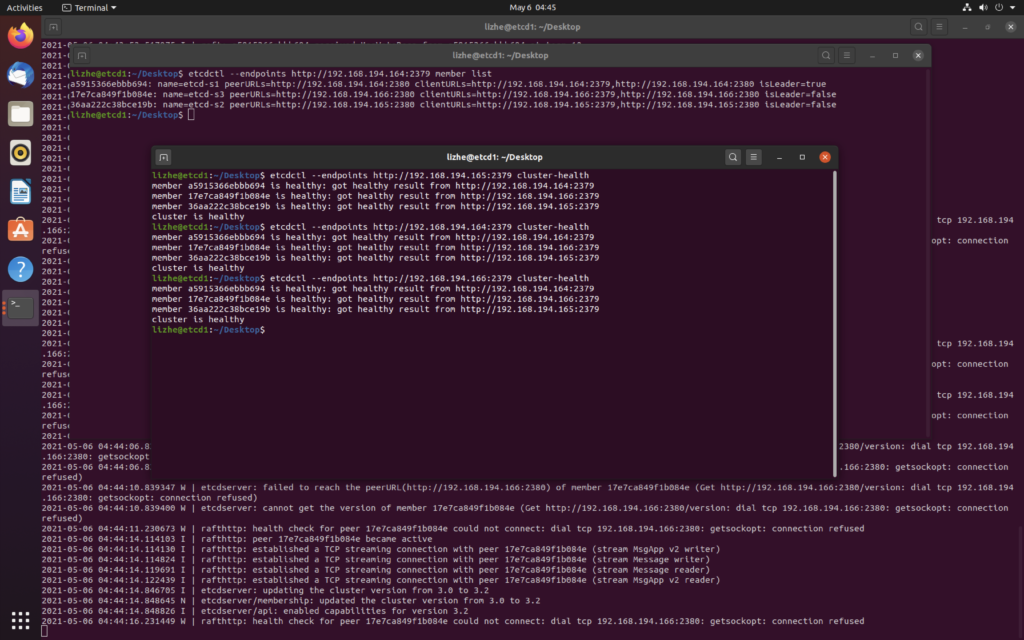
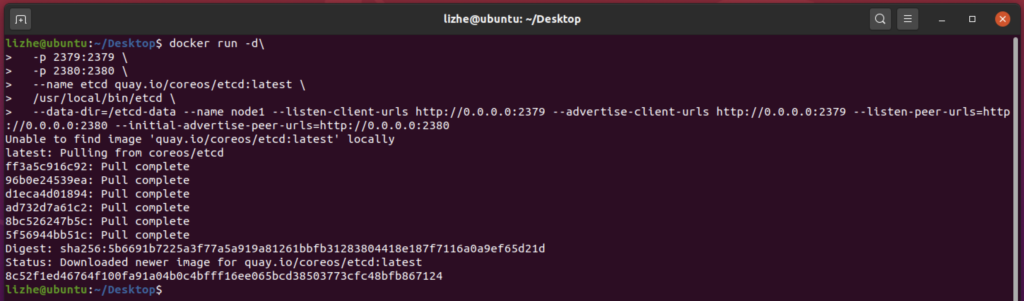
raft 算法主要使用两种方式来提高可理解性
- 问题分解
- 减少状态空间
raft协议组织的集群中,一共包含3类角色
raft 算法将时间划分成为任意个不同长度的任期,任期是单调递增的,用连续的数字 1、2、3 … 表示。
每一个任期,都是由一次选举人选举开始的。
每个任期只能选举出一个领导人,如果选票被平分,那么本次选举失败,系统会直接进入下一任期
每一个raft节点各自都在本地维护一个当前任期值,增加这个数字以进入下一任期
主要有两种场景:开始选举 和 与其他节点交换信息
当节点进行通信时,会相互交换当前的任期号。如果一个节点的当前任期号比其他节点的任期号小,则将自己本地的任期号自觉地更新为较大的任期号。如果一个候选人或领导人意识到自己的任期号过时了(比别人小),那么它会立刻切换回群众状态,如果一个节点收到的 拉票请求 锁携带的任期号是过时的,那么该节点就会拒绝本次拉票请求。
领导人选举
raft 通过选举一个权力至高无上的领导人,并采取赋予它管理复制日志权力的方式来维护节点间日志的一致性。领导人从客户端接收日志条目,再把日志条目复制到其他服务器上,并且在保证安全的前提下,告诉其他服务器将日志条目应用它们的状态机中。
每个候选人携带一个 “造反计时器”,并且每个选举人的计时器时间是随机的,各不相同。
领导人会定时向各个节点发送 “不要造反心跳”,各节点接收到 “不要造反心跳” 后,会重置自己的 “造反计时器”,为了避免频繁地发生选举,Leader广播心跳的周期会小于 “造反计时器” (选举定时器)的超时时间。
如果一个Follower决定参加选举,那么它会执行以下步骤
- 把自己的任期号 +1
- 切换自己到候选人状态
- 向其他节点发送 拉票请求(带着自己的新任期号)
然后它可能会得到以下结果
- 成功拉票超过半数,成为Leader
- 发现已经有节点在自己之前成功当选,主动切换回 Follower
- 过了一段时间之后,发现没有人赢得选举,重新发起一次选举
日志复制
一旦某个领导人赢得了选举,那么它就会开始接受客户端的请求。
客户端请求都将被解析成一条需要复制状态机执行的指令。领导人节点把这条指令作为一个新的日志条目加入它的日志文件中,然后并行地向其他raft节点发起 AppendEntries RPC,要求其他节点复制这个日志条目。
过半数节点复制成功之后,领导人节点会发起 apply 指令将这条日志应用到它的状态机中,并向客户端返回,然后再向其他节点广播应用消息。
这里因为 Follower 节点会无条件的服从 Leader,如果Leader在响应了客户端请求之后(日志已经分发,但是还没有apply)发生了故障,那么新当选的 leader 和 之前的leader 数据可能发生冲突。所以在raft中有一个重要限制, 任何领导人都必须拥有之前任期提交的全部日志条目
raft采用拉票的方式来保证这一机制,当候选人进行拉票时,投票人会检查候选人提交的最新日志条目是否大于等于自己本地的条目,如果候选人的条目没有比自己的日志条目更新,那么选举人将拒绝此次投票请求。比较的依据是日志文件中最后一个条目的索引和任期号