可以把 布隆过滤器 理解成一种特殊的,不太精确的set结构,当你使用它的 contains方法判断某个对象是否存在时,它可能会误判。
当 布隆过滤器 说某个值存在时,这个值可能不存在。
当 布隆过滤器 说某个值不存在时,这个值肯定不存在。
Bloom 过滤器是一种插件,也可以直接用安装好的镜像
docker run -i -t -d --name redisbloom -p 6379 redislabs/rebloom下面是一些操作例子
127.0.0.1:6379> bf.add students lizhe
(integer) 1
127.0.0.1:6379> bf.add students jon
(integer) 1
127.0.0.1:6379> bf.exists students lizhe
(integer) 1
127.0.0.1:6379> bf.mexists students lizhe jon tony
1) (integer) 1
2) (integer) 1
3) (integer) 0
127.0.0.1:6379> bf.madd students user1 user2 user3
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> del students user1
(integer) 1
127.0.0.1:6379> del students user2
(integer) 0
127.0.0.1:6379> del students user3
(integer) 0
127.0.0.1:6379>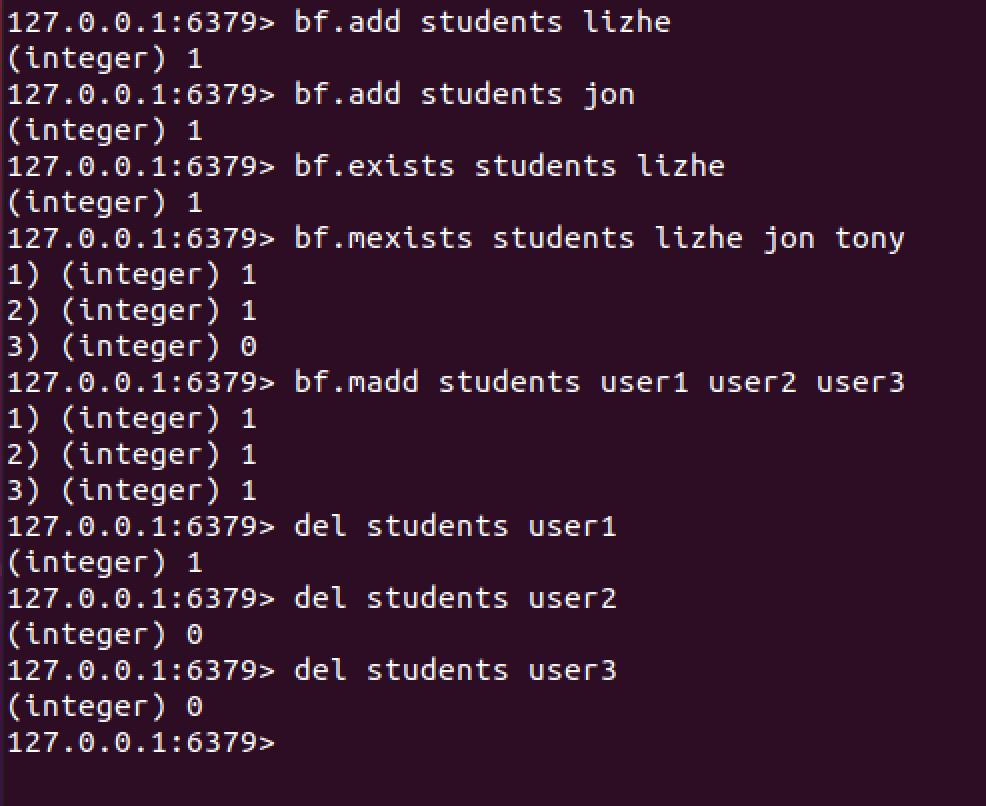
每个布隆过滤器对应的 redis 数据结构 是一个大型的 位数组 和几个不一样的 无偏 hash 函数
所谓无偏,就是能把元素的hash值算得比较均匀,让元素被hash映射到位数组中的位置比较随机。
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash,算得一个整数索引值,然后对位数组长度进行取模算得一个位置,每个hash函数都会算得一个不同的位置,再把这些位置都设置为 1 , 就完成了 add 动作。
询问元素是否存在时,也会把hash再算一遍,确定出需要为 1 的位置,去和存储的内容进行比对,如果 1 的位置完全匹配,那么就为 “存在”,如果有一个位置为 0 , 就为 “不存在”,但是有些时候,如果 2个不同元素的 所有 1 的位置都相同,那么就会出现 “误报”
还有一个需要注意的地方是, 布隆过滤器不会误判那些 “已经见过的元素”,它只会误判那些没见过的元素。
也就是说误判会出现在,如果你给它一个没见过的元素,看看它是不是以为自己见过了
要降低 error_rate,就需要更大的存储空间,默认的 error_rate 是 0.01 , initial_size 是 100
如果要修改默认的参数需要调用
127.0.0.1:6379> bf.reserve students 0.001 1000
OK
127.0.0.1:6379> 
布隆过滤器的 initial_size 太大会浪费存储空间,设置过小,会影响准确率。
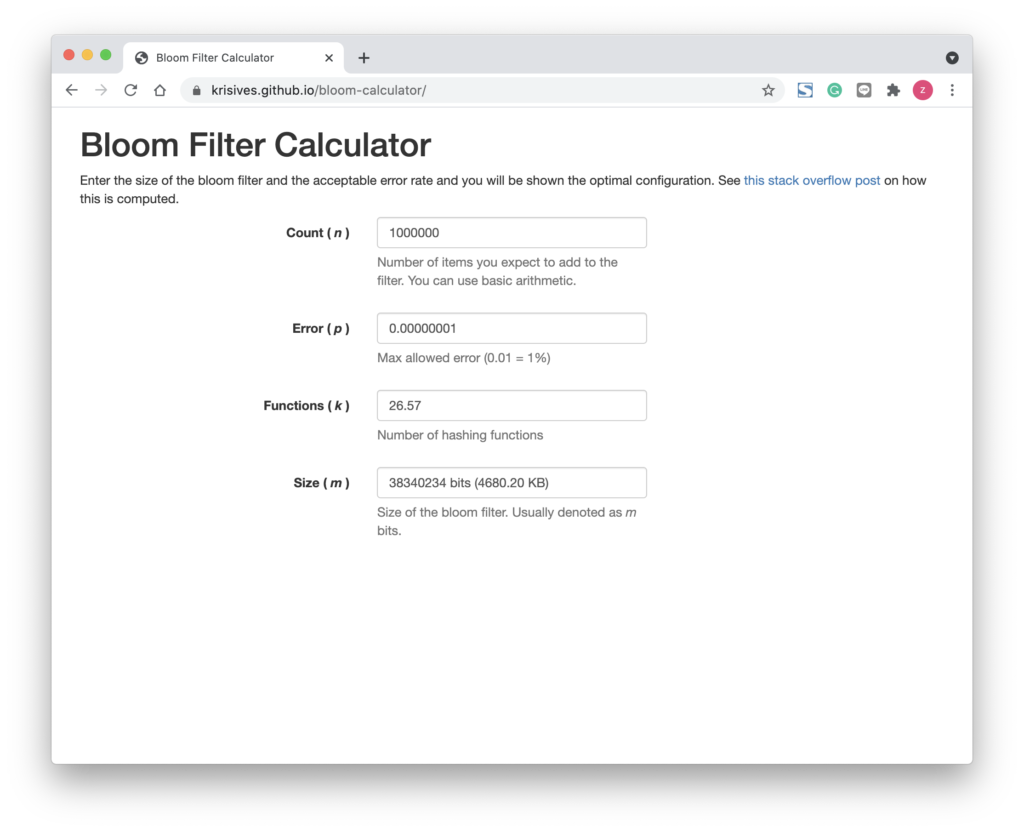
那么如何来判断布隆过滤器的空间占用呢?这里有一个简单的公式
k = hash函数的最佳数量
n = 元素数量
f = 错误率
k = 0.7 * ( 1/n )
f = 0.6185 ^ ( 1/n )
^ 次方操作, math.pow
https://krisives.github.io/bloom-calculator