Scheduler 是以一种 多人负责同一工作,然后基于投票激活一个主工作节点 的方式运作的。
领导者选举机制可以保证高可用性,但是正常工作的Scheduler节点只有一个,其他节点作为候选节点处于阻塞状态。
在领导者节点因某些原因而退出后,其他候选节点则通过选举机制竞选,成为新领导的节点将接替原来节点的工作。
选举机制是通过分布式锁来实现的,
- 分布式锁依赖于 Etcd 上的一个 key,key 的操作都是原子操作,将 key 作为分布式锁,它有两种状态——存在和不存在。
- key(分布式锁)不存在时:多节点中的一个节点成功创建该 key(获得锁)并写入自身节点的信息,获得锁的节点被称为领导者节点。领导者节点会定时更新(续约)该 key 的信息。
- key(分布式锁)存在时:其他节点处于阻塞状态并定时获取锁,这些节点被称为候选节点。候选节点定时获取锁的过程如下:定时获取 key 的数据,验证数据中领导者租约是否到期,如果未到期则不能抢占它,如果已到期则更新 key 并写入自身节点的信息,更新成功则成为领导者节点。
我们都知道调度器的主要功能是 为新创建的pod ( 实际上如果pod出现需要迁移的情况也一样 )在集群中寻找最合适的 node 节点,并将pod调度到这个节点上。
1. 先选可用节点
2. 再选最优节点
3. 如果使用 pod.spec.nodeName 则强制约束将 pod 调度到指定节点,绕过调度器并不会做和人的资源检查
调度核心为两个独立的控制循环
一个是 Informer Path 循环上 list-watch 机制 和 cache 机制
一个是 Scheduler Path 循环上的 预选优选机制 和 绑定回调机制
第一个控制循环 Informer Path
主要目的启动一系列的Informer,用来监听(list-watch)Etcd 中Pod、Node、Sservice等与调度相关的API对象的变化。
例:当一个待调度pod(nodename字段为空)被创建,调度器会通过Pod Informer的Handler,将待调度的pod添加进调度队列。
默认情况,kubernetes调度队列是一个PriorityQueue(优先级队列),并且当某些集群信息发生变化的时候,调度器会对调度队列中的内容进行特殊操作。主要是出于调度优先级和抢占的考虑。
负责对调度器缓存(scheduler cache)进行更新。Kubernetes调度部分进行性能优化的最根本原则,尽最大可能将集群信息Cache化,提高Predicate和Priority调度算法的执行效率。
第二个控制循环,调度器负责pod调度的主循环scheduling path
主要逻辑:不断从调度队列出队Pod,调用Predicates算法进行“过滤”。“过滤”得到一组Node,就是所有可以运行这个Pod的宿主机列表。Predicates算法需要的Node信息,从scheduler cache直接获取,保障算法执行效率。
调度器会调用Priorities算法为上述列表的Node打分,分数从0-10。得分最高的Node,作为调度的结果。
调度算法执行完成之后,调度器就需要将Pod对象的nodeName字段的值,填充为Node名字。 ====> Bind阶段。
具体位置在
/home/lizhe/k8s/kubernetes/pkg/scheduler/scheduler.go
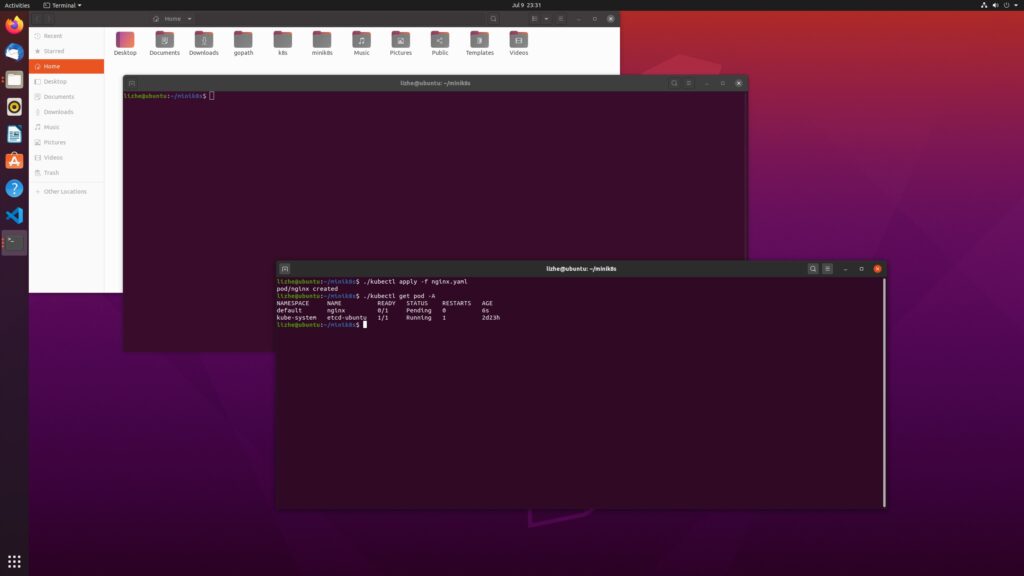
这里我去掉前面例子中的 nodeName,重新apply nginx
可以看到在不启动 kube-scheduler 的情况下,pod 无法被正确分配到 node ,会一直处于pending状态
启动 kube-scheduler
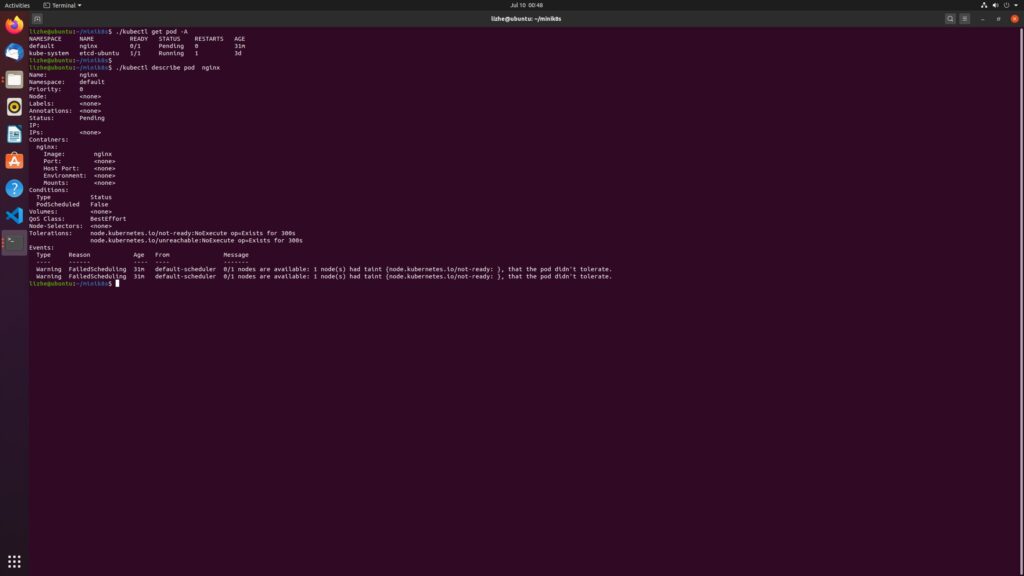
./kube-scheduler --kubeconfig=kubeconfig.yaml重新创建 nginx pod 你会发现仍然是pending
通过查看 pod 信息发现,原来是 node 默认持有不被分配的 污点 taint
下一步我尝试删除这个 taint
./kubectl taint nodes ubuntu node.kubernetes.io/not-ready:PreferNoSchedule-
./kubectl taint nodes ubuntu node.kubernetes.io/not-ready:NoSchedule-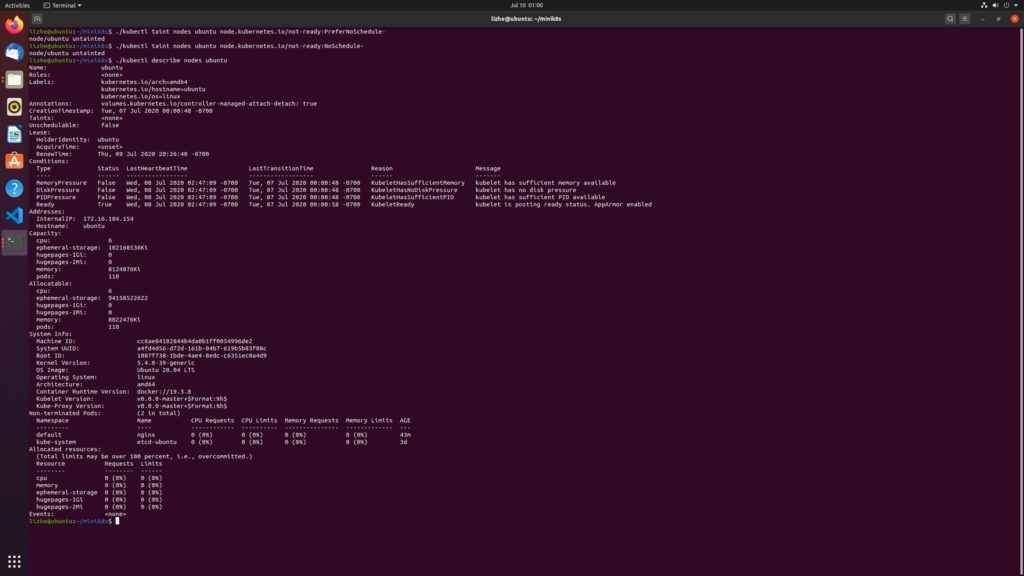
删除 taint 之后可以看到 scheduler 确实为 pod 分配了 node
可是 pod 状态仍然是 pending
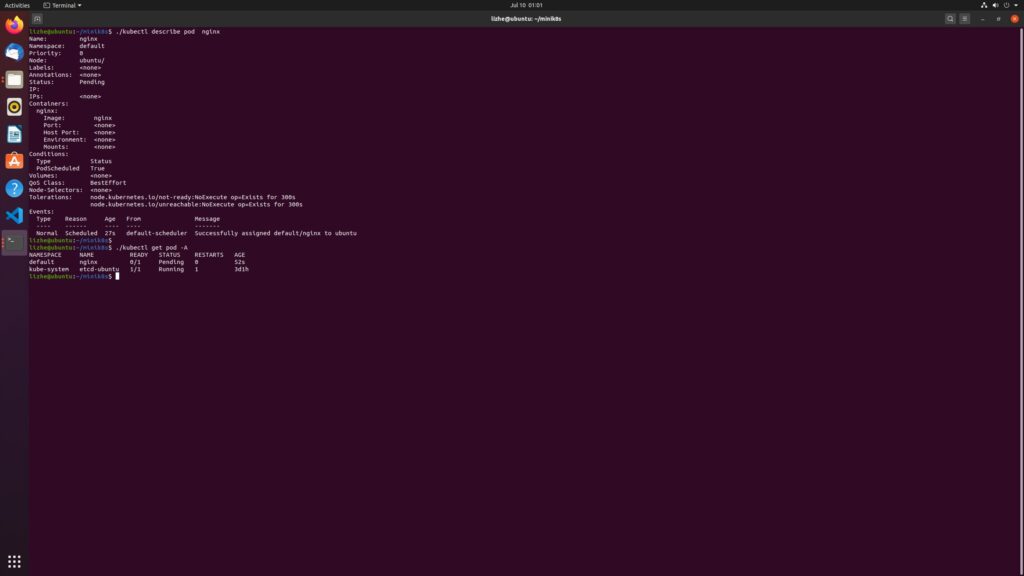
我们已经看到了 scheduler 成功分配了 node
但是,kubelet 似乎没有正确创建 pod 的 instance, pod的状态仍然是 pending,这是为什么呢?我们在下期揭晓







