上一篇文章里我们启动了 scheduler 之后,pod 确实被自动分配了,但是状态却仍然是pending
请参阅 Kube-scheduler
这里的根本原因是我们还没有启动 kube-controller-manager ,
Controller Manager 作为集群内部的管理控制中心,负责集群内的Node、Pod副本、服务端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的管理,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。还是使用我们的config文件,启动 kube-controller-manager
kube-controller-manager 包含以下组件
Replication Controller
Node Controller
CronJob Controller
Daemon Controller
Deployment Controller
Endpoint Controller
Garbage Collector
Namespace Controller
Job Controller
Pod AutoScaler
RelicaSet
Service Controller
ServiceAccount Controller
StatefulSet Controller
Volume Controller
Resource quota Controller
cloud-controller-manager 只有在启用了 Cloud Provider 的时候才需要,用来配合云服务商提供的控制
Node Controller
Route Controller
Service Controller
使用下面的 kubeconfig.yaml 启动 controller manager ,在 controller manager 启动之后可以看到 pod 被正确创建了
apiVersion: v1
kind: Config
clusters:
- cluster:
server: http://127.0.0.1:8080
name: mink8s
contexts:
- context:
cluster: mink8s
name: mink8s
current-context: mink8s./kube-controller-manager --kubeconfig=kubeconfig.yaml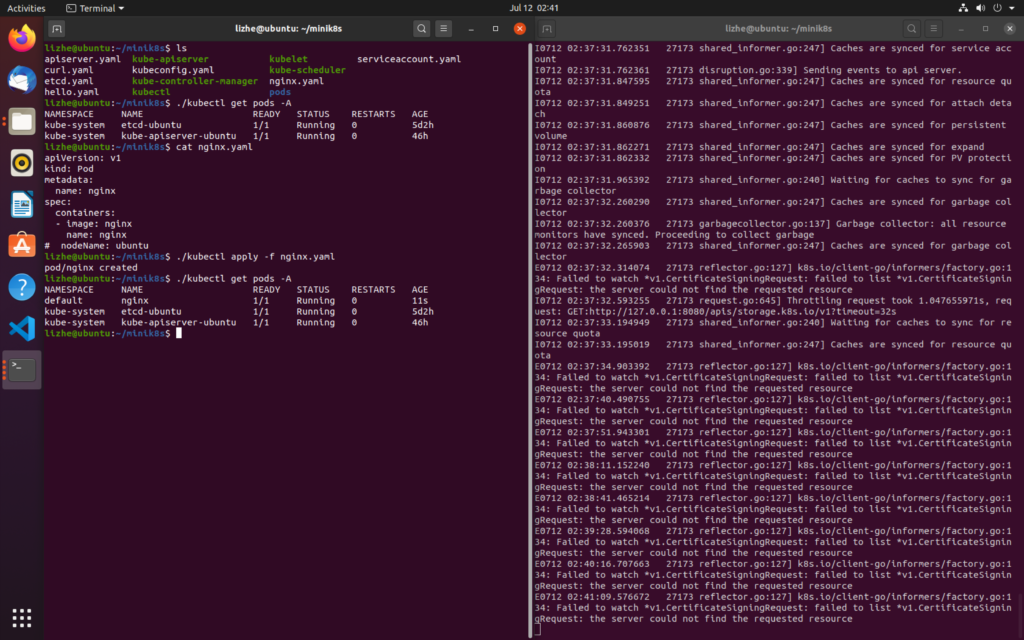
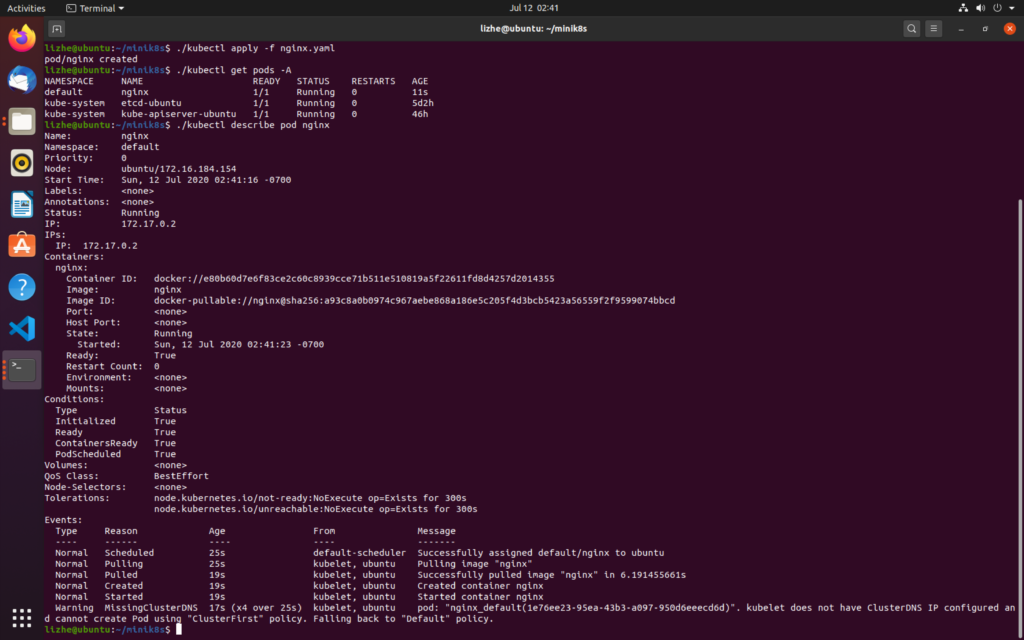
kukubernetes采用租赁锁(lease-lock)实现kube-controller-manager 的 leader的选举,并且可以由启动参数”–leader-elect=true”控制
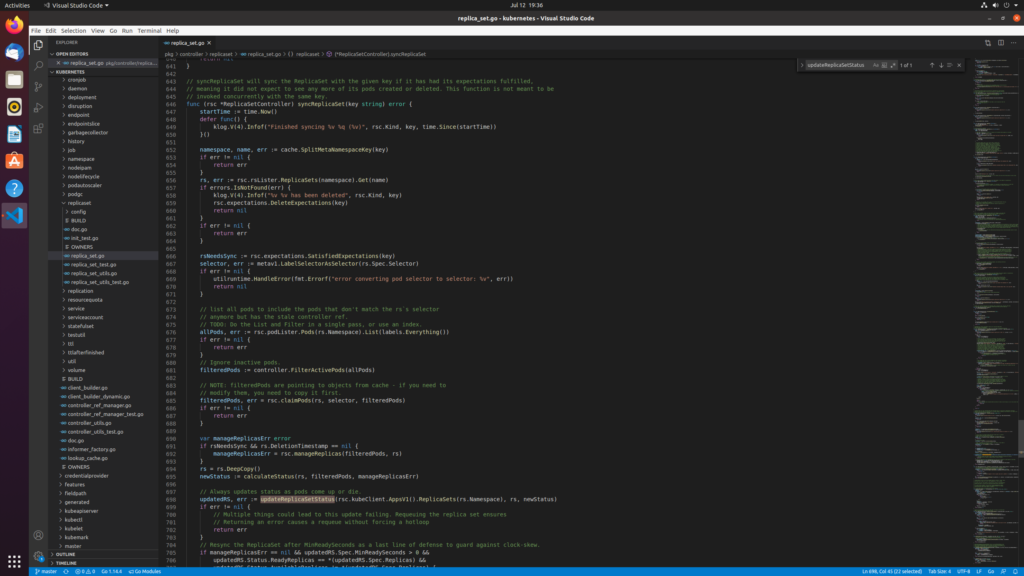
ReplicaSetController 是 Controller Manager 中比较重要的一个部分
只有当Pod的重启策略是Always的时候(RestartPolicy=Always),副本控制器才会管理该Pod的操作(创建、销毁、重启等)
RC中的Pod模板就像一个模具,模具制造出来的东西一旦离开模具,它们之间就再没关系了。一旦Pod被创建,无论模板如何变化,也不会影响到已经创建的Pod。
Pod可以通过修改label来脱离RC的管控,该方法可以用于将Pod从集群中迁移,数据修复等调试
在pod死亡或者新建时更新状态
controller-manager中PodGCController的清理依据
1.gc掉超过阈值限制的pod,按时间排序gc
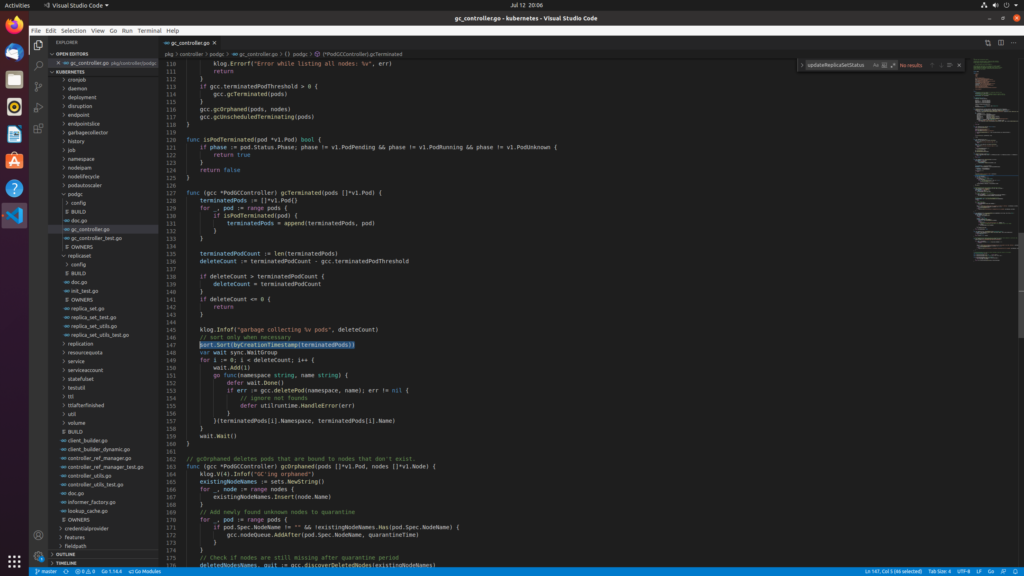
2.gc掉孤儿pod:pod上的node信息不在当前可调度的节点上,即没有和有效node绑定
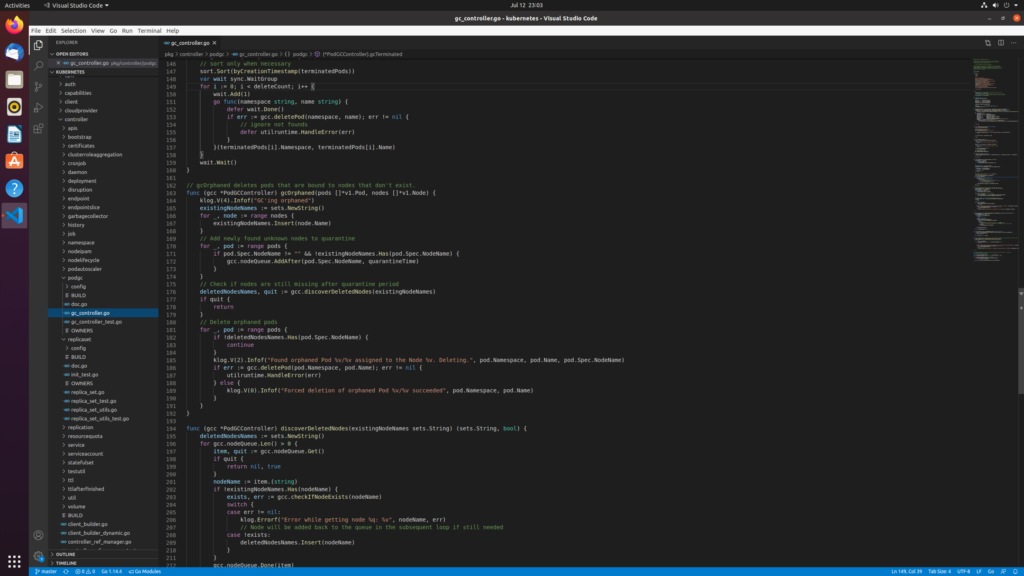
3.gc掉没有调度成功的pod:表现在pod的NodeName为空,主要由于资源等条件不满足
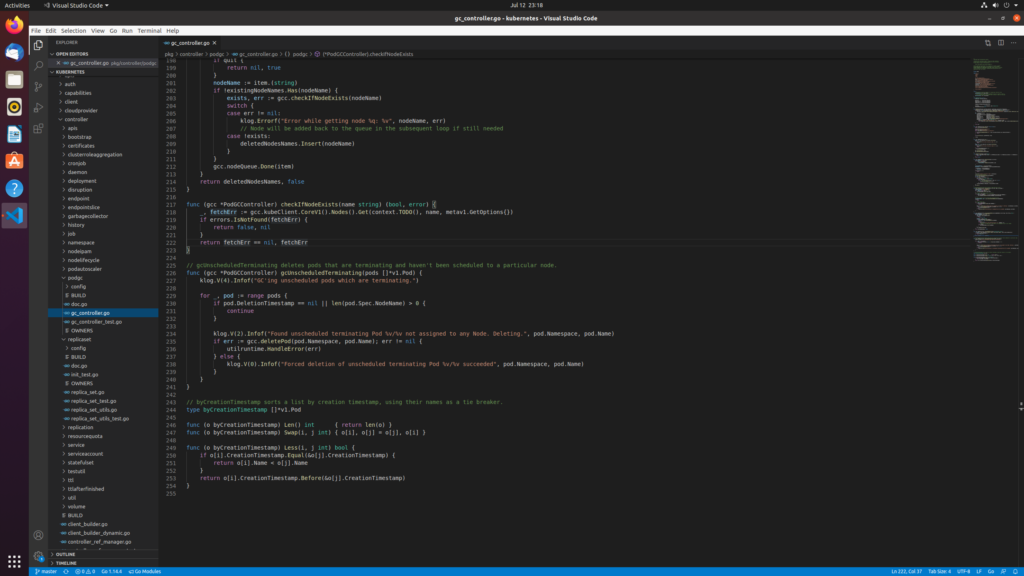
end
如果按照上面内容启动之后 你的pod仍然 pending
要注意 请按照下面顺序启动以下这三个组件
sudo ./kubelet --pod-manifest-path=pods --fail-swap-on=false --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.2 --kubeconfig=kubeconfig.yaml
./kube-scheduler --kubeconfig=kubeconfig.yaml
./kube-controller-manager --kubeconfig=kubeconfig.yaml






